SEP 11, 2024
Adaptive ASHA Explained using America’s Got Talent

October 11, 2023
In today’s world, it can feel impossible to keep up with the rapid pace of AI development. Newer algorithms seem to appear almost daily that continue to beat the state of the art in various domains.
One thing that’s stood the test of time, however, is Adaptive ASHA for hyperparameter search. In this blog, we’ll break down how the algorithm works, and explain it simply using America’s Got Talent. Get some popcorn, because this show is about to start 🍿
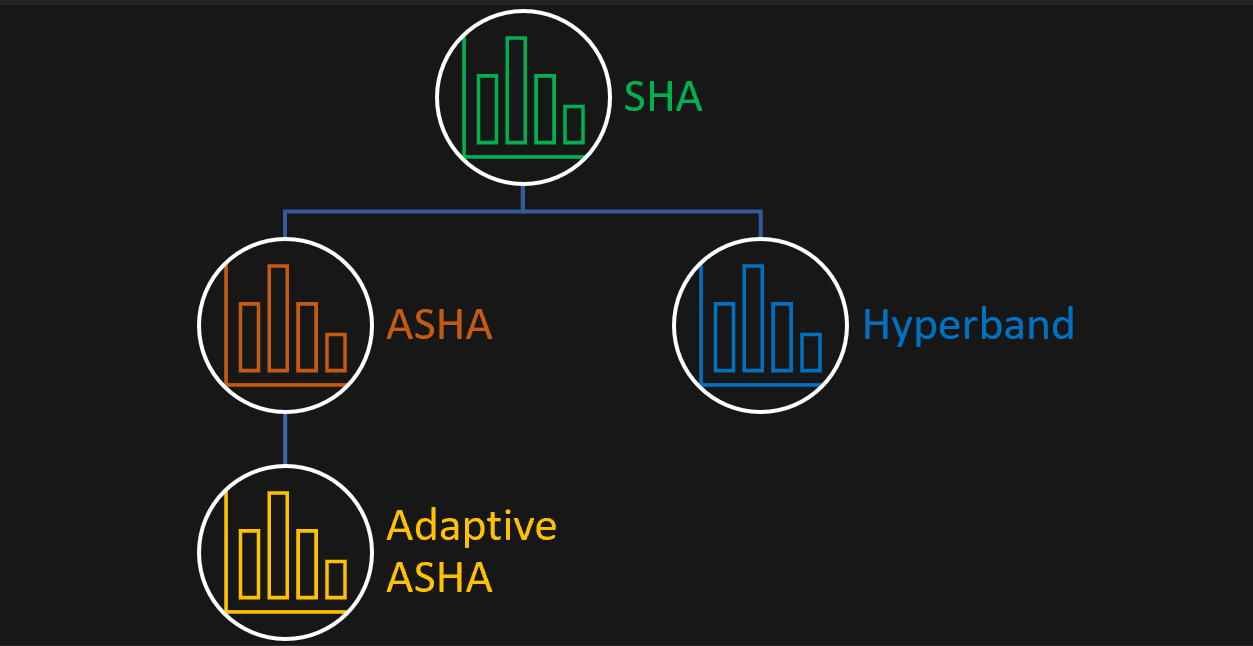
Adaptive ASHA is actually best explained as a series of improvements on top of one base algorithm: SHA. The “A” in ASHA is an improvement on top of SHA, and the “Adaptive” in Adaptive ASHA is another improvement. Let’s start off by breaking down SHA:
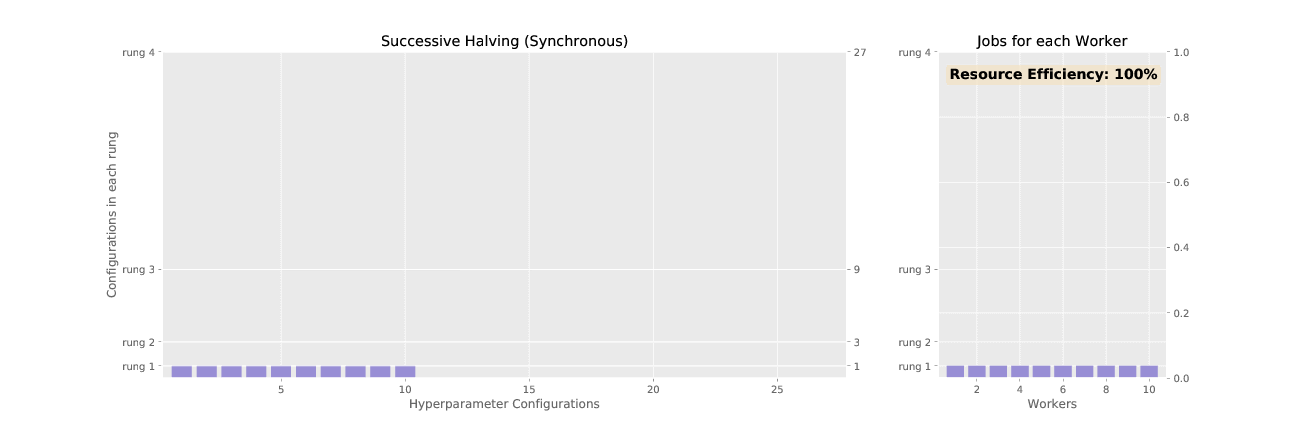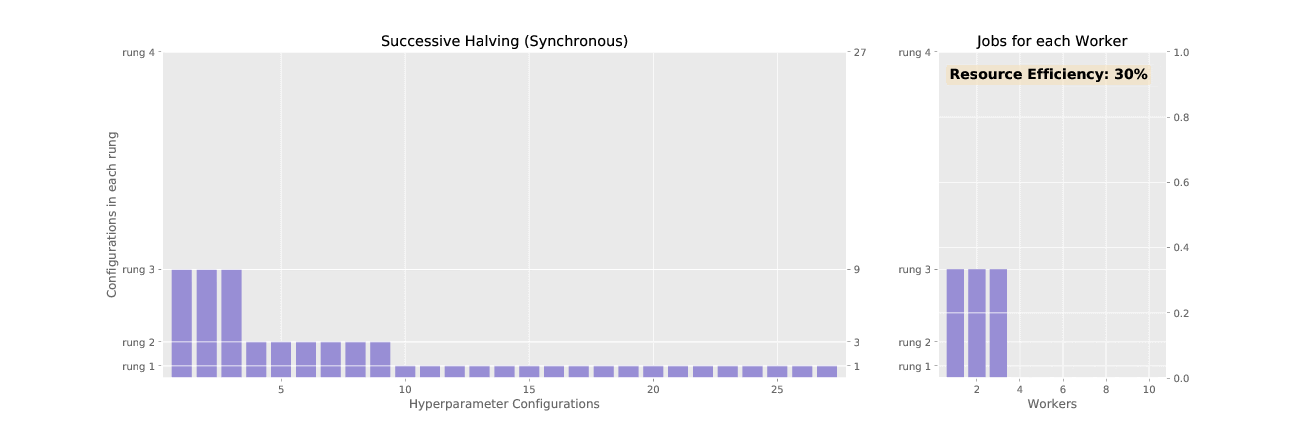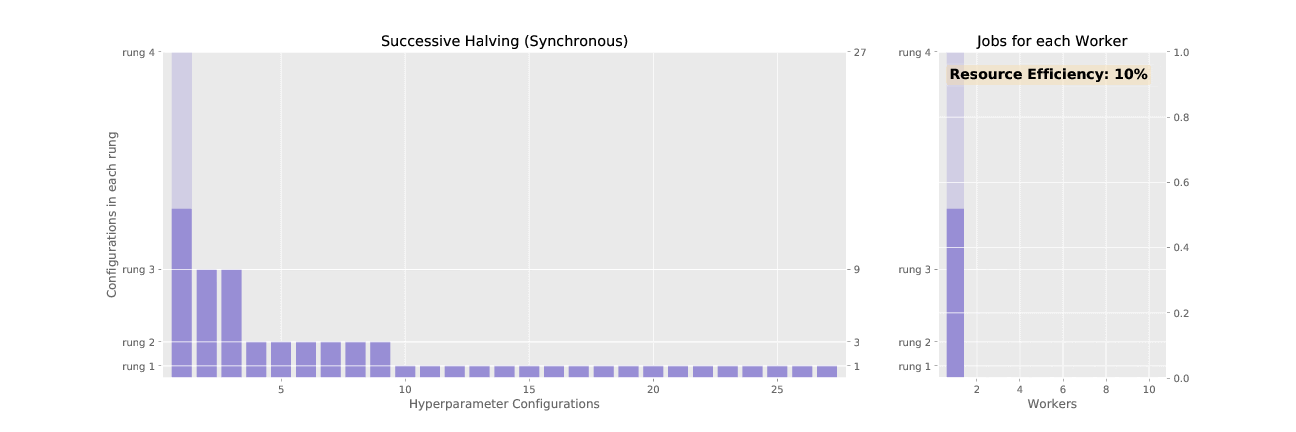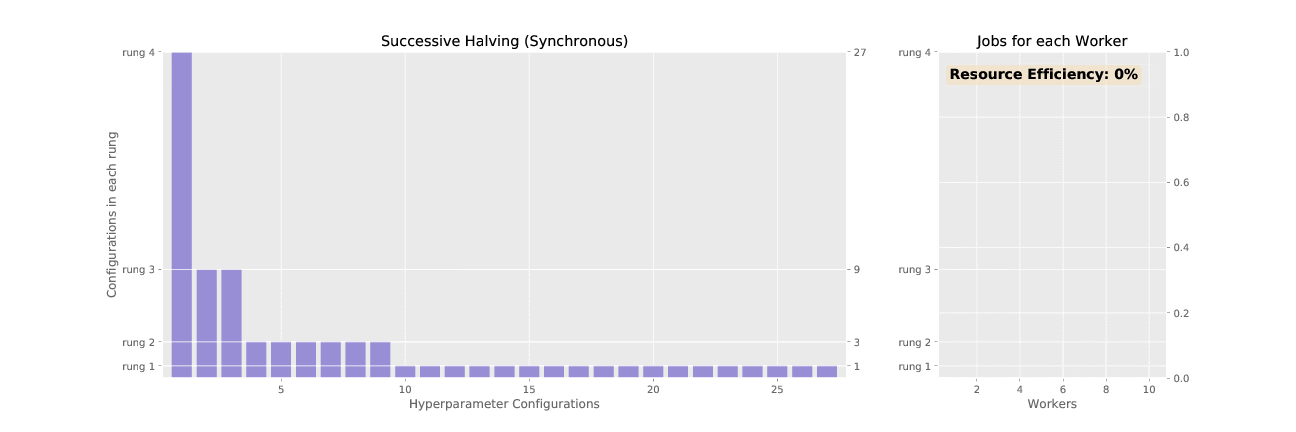
1. Successive Halving Algorithm (SHA):
In a hyperparameter search, the goal is to search within a search space for the parameters that maximize a model’s performance on some task. The successive halving algorithm is one way to do this.
In SHA, there are successive “rounds”. Within each round, a set number of trials is initialized with values from this search space, and a compute budget is allocated for each trial. Think of each “round” like an America’s Got Talent round, where each trial is like a singer, and the training budget is like the time given to each singer to prove their singing abilities.
As the rounds progress, the number of trials, or singers, is successively halved* based on performance. In each round, the budget grows bigger, and eventually, one trial is left, which is the winning hyperparameter search configuration.
*it does not have to actually be a halving, you can divide the number of rounds by a value n of your choosing.
2. Asynchronous Successive Halving Algorithm (ASHA):
What if there was a way to eliminate trials, or singers, early, before a round is over?
ASHA is designed for the “large-scale regime”, where it’s necessary to evaluate many, many more hyperparameter configurations. Just like it’s possible to guess that a singer has no talent without listening to them sing a full song, it’s possible to evaluate hyperparameter configurations more efficiently than letting each trial finish in each round before moving on to the next one.
ASHA works with rounds and budget increases in subsequent rounds just like SHA. But, instead of waiting for the entire round to complete, ASHA promotes trials to the next round whenever possible, like giving a singer with an exceptional voice the Golden Buzzer and promoting them to the next competition round immediately. Eliminating trials early is referred to as “early-stopping”.
Nuances:
- Sometimes ASHA promotes erroneously, but since it’s such a large scale search space, it doesn’t really matter.
- If there are no promotions possible, ASHA adds a configuration to the base round, so that more configurations can be promoted to higher rounds.
Here’s the difference between SHA and ASHA, visualized:
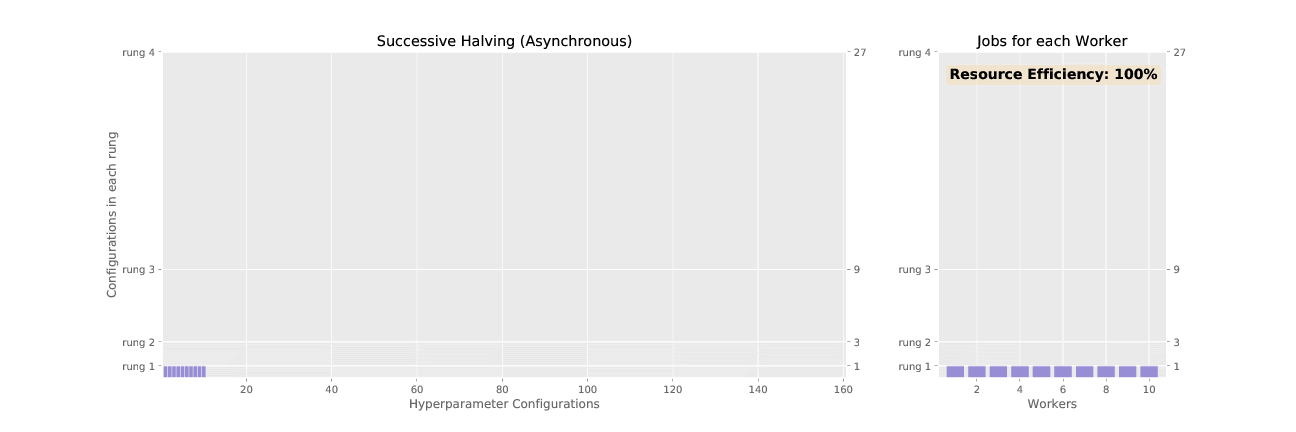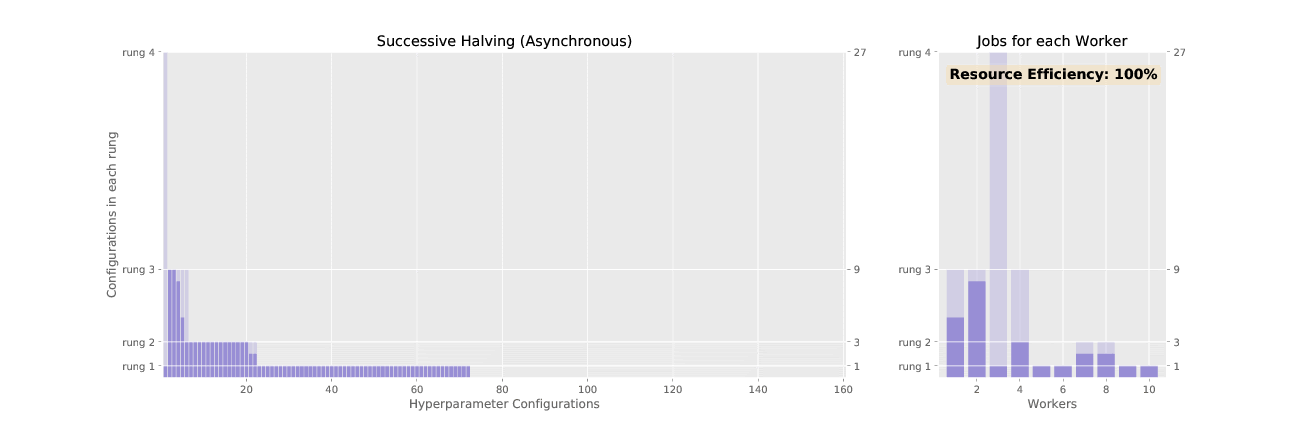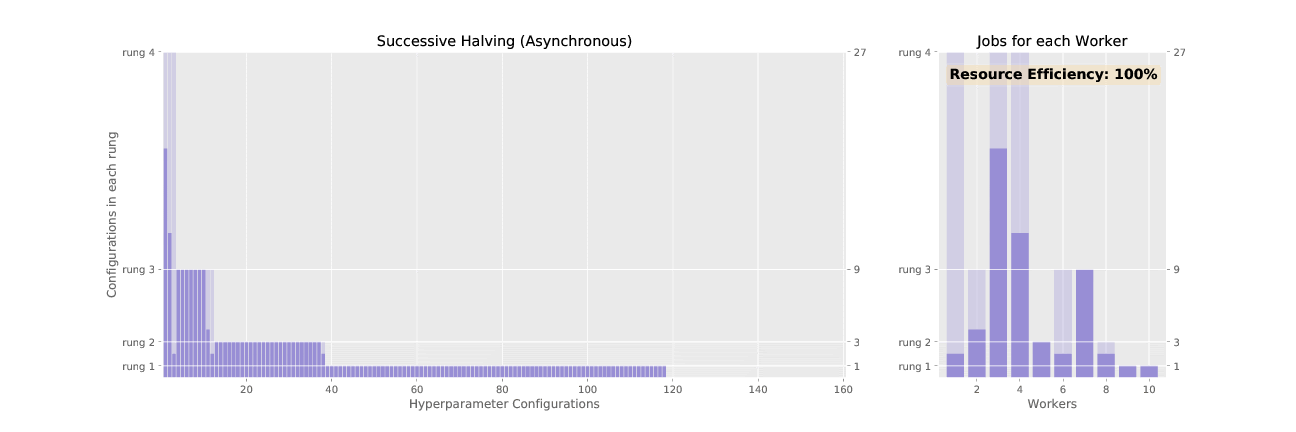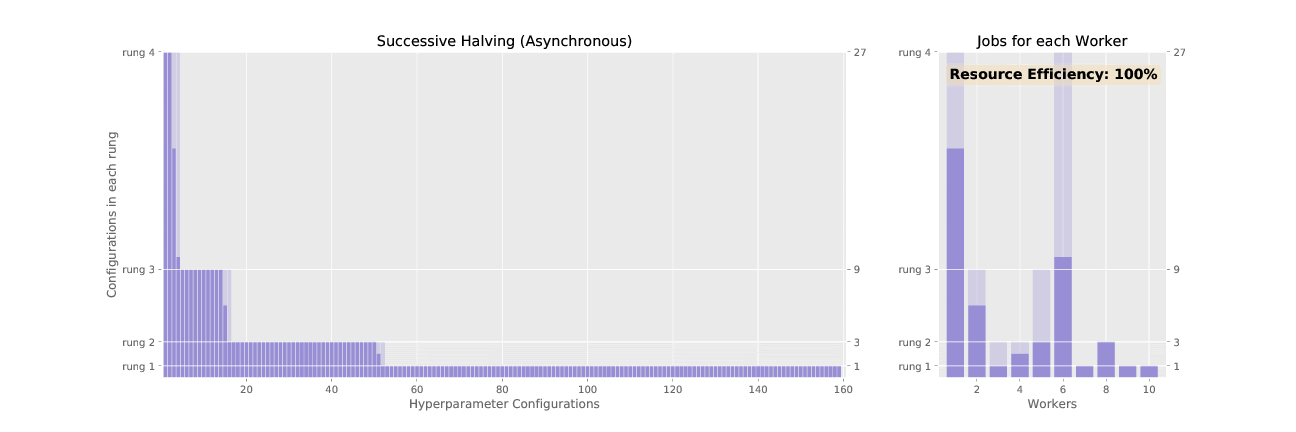
3. Adaptive ASHA:
Adaptive ASHA can be thought of as an America’s Got Talent championship. Adaptive ASHA would organize a bunch of individual competitions (ASHA routines) all running in parallel. Adaptive ASHA initializes each ASHA “competition” with different numbers of rounds and early stopping levels, like having aggressive judges that eliminate singers fast, vs. more patient judges. Adaptive ASHA solves the problem of not knowing what early stopping rate to use by trying different brackets of ASHA.
What are the benefits?
Adaptive ASHA outperforms other hyperparameter search algorithms like PBT, BOHB, and Vizier. It’s best suited for large scale hyperparameter search, but works very well across a variety of deep learning models and scales.
A quick note on Hyperband:
Hyperband is another hyperparameter search algorithm that is an improvement on SHA. Hyperband initializes a bunch of SHA trials, some with longer training times but fewer rounds, and some with shorter training times but with more rounds. Since it’s not clear which of those choices is more optimal, Hyperband considers them all in a grid search.
Hyperband vs. Adaptive ASHA
Think of Adaptive ASHA like a slightly more flexible version of Hyperband that wraps around ASHA instead of SHA. It biases towards more early stopping, but allows users to specify more conservative or more aggressive if they want. Here’s a visualization to make this more clear:
Future Direction
There have been many extensions to ASHA/Hyperband that combine adaptive selection of hyperparameter configurations with adaptive resource allocation, the most popular of which is BOHB. This is something we want to support in the future along with additional algorithms, like HEBO, for example.
Resources:
Conclusion
Hopefully, this helped you understand Adaptive ASHA a little better! There’s lots more information in our docs if you’re looking for a more detailed guide. As always, feel free to ping us in our Slack Community if you have any questions.