SEP 11, 2024
Use Batch Inference in Determined Part 1: Text Embedding Computation



July 25, 2023
We are pleased to announce the launch of a new Batch Processing API for batch inference use cases!
Previously, most of our APIs focused on training (documentation). While model training is a core part of a data scientist’s work, a complete workflow does not stop at training. For example, data scientists run inference with their trained models to compute embeddings or to perform additional model validation. In many cases, the sheer volume of data needed for these tasks often necessitates running inference in parallel with multiple model replicas.
Our new Batch Processing API expands Determined’s capabilities beyond model training by making model inference parallelization available and easy to use.
In this blog, we will introduce the Batch Processing API and cover one specific use case in more depth: text embedding computation.
Why is the Batch Processing API needed?
There are three common pain points we have heard from our users:
-
Lack of standardization: In the past, there was no out-of-box, easy-to-use, Determined native solution for our users to run batch inference. Core API based batch inference requires low-level understanding of parallel programming. Alternatively, users’ homegrown solutions to run batch inference lacked native support from Determined, (e.g., preemption, experiment tracking, metrics reporting, and codebase maintenance).
-
Batch inference is computationally heavy: Batch inference is often run on a large volume of data and is computationally expensive. While it may be trivial to write a script that runs inference with a single model, the sheer volume of data often necessitates running inference in parallel with multiple model replicas. This becomes complicated very quickly.
-
Model development workflow is slowed down by omitting batch inference: Users are limited to running smaller scale inference during prototyping, and sometimes don’t even realize the need to run batch inference. If users skip over batch inference during prototyping and move directly to productionizing, their model development gets slowed down.
How can Determined’s Batch Processing API address these problems?
-
Make batch inference a first-class citizen in your workflow: Just like the training experiment, the inference experiment will be visible in the Determined Web UI, and metrics will be reported and visualized in the Determined UI. In addition, users can pause and resume the inference experiment in the Determined UI, and checkpoints help you resume your batch inference experiment.
-
Speed up your batch inference with multiple GPUs: The Batch Processing API abstracts away low-level parallel programming and handles synchronization between workers and preemption under the hood (see this example for how the new API abstracts away the complexity).
-
Increase prototyping velocity with flexibility: Batch inference can be run on the fly, regardless of development stage. This flexibility increases prototyping velocity, making the user journey seamless from prototyping to productionizing.
Introducing the Batch Processing API
The Batch Processing API helps you 1) shard the dataset across multiple workers, 2) apply your processing logic to batches of data, and 3) keep track of progress in case you pause and resume your experiment. Essentially, all the features Determined offers for training your model are now available via the Batch Processing API for non model training workloads as well, including coordination between workers and pause/resume functionality.
The Batch Processing API works similarly to Determined Trial APIs for training. You build a processor class that inherits from TorchBatchProcessor:
class MyProcessor(TorchBatchProcessor):
def __init__(self, context):
self.context = context
self.model = context.prepare_model_for_inference(get_model())
def process_batch(self, batch, batch_idx) -> None:
predictions = self.model(batch)
The two methods that users must implement are __init__, which is where resources can be initialized (e.g., models, tokenizers), and process_batch, which implements the processing logic for each batch of data.
Optionally, users can also implement on_checkpoint_start and on_finish methods to define logic to be executed at those specific lifecycle points. A template is located here for your convenience.
For example, here’s what a main function would look like if you wanted to run inference on a Huggingface’s BeIR/scidocs dataset:
if __name__ == "__main__":
dataset = load_dataset("BeIR/scidocs", "corpus", split="corpus")
experimental.torch_batch_process(
EmbeddingProcessor,
dataset,
batch_size=64,
checkpoint_interval=10
)
Use Case: Text Embeddings Computation
Why do we need to compute document embeddings?
Chat or question-and-answer applications powered by LLMs are increasingly common. Prompts to the LLM are often supplemented with relevant documents to improve answer quality. Embedding generation is the first step of this workflow.
What is vector embedding?
Embedding computation refers to a process where high-dimensional data (like words, phrases, or entire documents) are mapped to vectors of real numbers in a lower-dimensional space (an embedding space). For information retrieval applications, vectors in this embedding space map semantically similar input data (e.g., words with similar meanings; phrase with similar sentiment; visually similar images) together in the embedding space. Storing these vectors in a vector database enables users to capture the inherent structure and relationship of the original data.
Text embeddings of related documents will be closer together in the embedding space; thus, a vector database will be able to return relevant documents using vector similarity search techniques. Converting input data to the vector format to allow this search to take place requires running inference using an embedding model on a large volume of data, and this is where our new Batch Processing API can help.
How to use the Batch Processing API for distributed embedding generation?
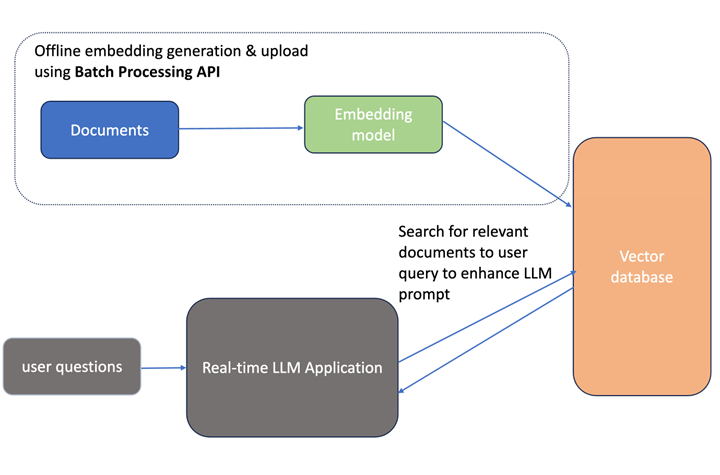
The diagram below illustrates the steps involved in embedding computation:
-
Batch Processing API is used to create the vector embeddings for various documents
-
embeddings are uploaded to a vector database
Later, real-time LLM applications will query the vector database to locate documents most relevant to user questions.
A detailed code example is here. Below is a high-level overview of the example:
The class we implement is the EmbeddingProcessor, which extends TorchBatchProcessor.
-
In the init function, all workers download and initialize the embedding model.
-
In the
process_batchfunction, all workers run inference and generate the embeddings. -
In the
on_checkpoint_startfunction, all workers persist the embeddings to files on the shared file system. -
In the
on_finishfunction, the chief worker initializes a vector database client and creates a collection. Next, it reads all the embeddings files into memory and inserts the embeddings into the vector database.
We can now query relevant documents from the vector database for a given input! We would embed the input text with the same embedding model and query the vector database with the embeddings generated.
For example, below is the result for the input “Data mining techniques”:

Summary
The Batch Processing API helps you address pain points in batch inference use cases outside of model training, for example, embedding computation, especially with large datasets. This solution makes batch inference Determined native, flexible, and easy-to-use.
Now the batch processing API is ready for you to try. To get started, please read the documentation and join our open-source community Slack channel! As always, we are here to support you and are open to your feedback.