SEP 11, 2024
Choosing Your Deep Learning Infrastructure: The Cloud vs. On-Prem Debate


July 30, 2020
This blog originally was published in June 2018. It's since been updated to reflect trend and pricing shifts over the past two years.
You’ve probably had some version of this debate many times: cloud or on-premise (or both)? Maybe you want to migrate parts of your application to the cloud. Alternatively, in light of recent data privacy policy changes, you may want to move some customer data back on-prem. Finally, perhaps your capacity needs are so bursty that it makes sense to invest in on-premise for your baseline infrastructure capacity needs but leverage the cloud when infrastructure demand spikes (i.e., a hybrid cloud model).
Just because you’ve made one choice for some of your infrastructure doesn’t mean the same answer will apply to your approach to deep learning. Training deep neural networks involves unique requirements that fundamentally change this discussion. These include:
- Specialized hardware accelerators, most often GPUs
- Storage for massive training datasets that only continue to grow
- High performance I/O between this specialized hardware and high volume storage
While the emergent trend in IT has been a migration to the cloud, we argue that these requirements may warrant on-prem infrastructure investment for deep learning at scale, particularly when high baseline GPU capacity is needed.
When you’re first getting started with deep learning, a cloud provider makes sense. With minimal up-front investment, both in dollars and time, you can get your first model training on a GPU. However, as your one-person team grows to five, and your single experiment becomes hundreds or even thousands, the cost savings in going on-prem can reach almost 10X over the big public clouds. Add to that the increased flexibility in what you can build and better data security, and suddenly on-prem starts to look increasingly appealing for your burgeoning deep learning ambitions.
Now, let’s dive into a little more detail to explain our reasoning. As we see it, you have four choices.
Cloud
- Traditional Cloud Provider: Large cloud vendors such as Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure.
- Machine Learning Specific Cloud Provider: Companies like Paperspace tailor their offerings to better support deep learning workflows (e.g., by focusing on GPU instances and additional software capabilities).
On-Prem
- Pre-Built Deep Learning Servers: Nvidia sells deep learning workstations, like its DGX systems. Other companies, like Lambda Labs, AMAX, and Boxx, build custom workstations based on your needs.
- Built-from-scratch Deep Learning Workstations: There are a ton of resources with step by step walkthroughs on what components to buy and how to get set up. See examples here, here, and here.
Next, we’ll compare how these options perform across our five most important criteria. Our analysis is summarized in the table below.

Performance
GPUs have become the standard for training deep learning models thanks to their high memory bandwidth and ability to do lots of parallel computation. The performance of your deep learning infrastructure is directly related to the quality of the GPUs it uses.
With new hardware releases and changes to offerings by cloud providers, answers here can quickly become outdated. For example, had we written this post a few years ago, on-prem would have been the clear winner in this category. AWS offered access to its p2 instances, which were built around Nvidia K80 cards (launched in 2014). However, if you had built your own workstation, you could have used newer cards, like the Nvidia Titan X (August 2016) or GTX 1080 Ti (March 2017), which deliver higher performance.
Cloud providers have since substantially upgraded their GPU offerings. AWS’s p3 instance type, their latest generation of general-purpose GPU instances, launched in October 2017 and offered Nvidia’s V100 GPU, which can deliver over 100 TFLOPS peak performance for training and inference. Azure and GCP shortly followed suit, making the V100’s available in March and April 2018, respectively. More recently, in May 2020, Nvidia released the Ampere-based A100 accelerator, which is already available in GCP’s alpha program, with plans to be generally available later in 2020.
On-prem users have the freedom to choose which GPUs to use. While you could buy yourself an Nvidia DGX Station with 8 A100 GPUs, you could also choose to build a rig with cards from the company’s consumer line. Thankfully, there are lots of resources out there benchmarking the relative performance of these models on deep learning workloads to help guide your decision.1,2 Ultimately, because you can now access the same top-of-the-line GPU models both in the cloud and on-prem, we score this category as a tie between the two options.
Beyond the GPU itself, high performance I/O is also crucial to accelerating model training time. Without sufficiently fast data transfer from remote or even local storage, your massively powerful GPUs will sit idle. Again, there shouldn’t be much of a performance delta between cloud and on-prem solutions here, as both make it possible to utilize the fastest types of local and remote storage, namely NVMe-based SSDs. However, we mention this to emphasize that properly designing your storage subsystem to keep pace with your GPUs is essential to achieving optimal performance.3
Pricing
We performed our own pricing analysis as of July 2020 with samples from each of the four categories. For the cloud options, we looked at AWS and GCP when considering “traditional cloud providers” and chose Paperspace as our “ML-specific” cloud provider.
We surveyed three performance levels - low, mid, and high - based on GPU model.4 We also considered two utilization assumptions: low (10%) and high (100%).
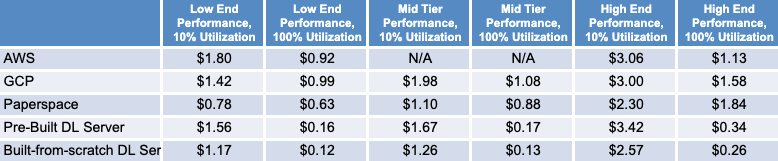
Utilization influences which pricing choice is most economical from the cloud providers. Assuming high utilization, you’ll want to use reserved instances, where you pay for continuous usage over a fixed period in exchange for a discounted hourly rate. Our analysis was optimistic, with the high utilization scenarios reporting prices assuming 3-year committed usage (which offers a greater discount relative to a 1-year contract). If your utilization isn’t sufficiently high, on-demand pricing is the better choice because you only pay for the instance when it’s running.5 The same is true for the ML cloud providers, who offer similar pricing models. Note that with these there’s also an extra monthly fee for their tool suite (with features like data visualization and 1-click Jupyter notebooks).
When considering the cost of on-prem, we included not only the up-front cost of acquiring and assembling the hardware, but also the cost of power, cooling, networking, and maintenance. To be generous to the cloud offerings, we estimated these costs as 50% of the hardware cost per year (amortizing over 3 years) for our analysis.6
Based on our analysis, on-prem solutions are the clear winners on price in high utilization cases, with the high-end and mid-tier built-from-scratch approaches coming in at 4.3X and 6.5X less than the cheapest cloud option, respectively.
Even in the low-utilization cases, on-prem is still cheaper than the traditional public cloud offerings at mid and high-performance levels. Though Paperspace appears to be the price winner for low utilization cases, this advantage is short-lived. By raising utilization to 11% on the high-end and 15% at the mid-tier, the built-from-scratch approach is back to price parity.
We’d argue that the high utilization scenario is the most important to focus on. Given the growth in datasets and model complexity, a single model can take days to train. Add to that the myriad of hyperparameters you’ll want to sweep to achieve optimal performance and you should have more than enough experiments to keep your hardware busy.
Setup
We think of setup as the amount of work required before you can start training your first deep learning model on a single GPU. In this category, the ML-specific cloud providers offer the most beginner-friendly solution. Their cloud instances come fully configured for deep learning, with CUDA, cuDNN, TensorFlow, and other popular deep learning frameworks pre-installed. They make it easy to launch Jupyter notebooks as well as access public datasets and sample projects. However, traditional cloud providers have started to catch up. With the AWS Deep Learning AMI, for example, you get a fully configured environment to run deep learning experiments. The most painful part of getting started with a cloud solution is likely uploading your dataset, which can be a slow and potentially expensive process (if there are data transfer costs out of the origin). It can also take several minutes to bring a stopped instance back online, which, even if not annoying the first time, adds up to a lot of wasted minutes if you’re doing this regularly.
On-prem solutions may require more up-front work, depending on what option you choose. For example, at Determined AI we recently purchased a pre-built deep learning workstation which required almost no setup. It came preloaded with Ubuntu, all of the necessary GPU drivers, and our favorite DL frameworks. After plugging it in to power and ethernet, we were ready to go! With the built-from-scratch option, the setup effort is mostly concentrated in assembling the workstation. This can be a time consuming, and potentially expensive option (if you break any of your parts along the way). However, setup on the software side is easier than you might think. Though you may still have to install some drivers, thanks to the rise of containerization, you can easily get images for your deep learning framework of choice. With one “docker pull” you’re ready to start working with Keras, TensorFlow, or PyTorch (with all the underlying software dependencies like Python and NumPy taken care of).
Once your infrastructure solution is set up to handle basic deep learning training workloads, it is then easy to use Determined to convert your setup into a powerful platform that your entire team can use to streamline more advanced deep learning workloads.
Maintenance
Traditional providers come out ahead in this category, having built their business around providing continuous uptime. ML-specific providers also advertise SLAs (Paperspace, for example, promises 99.99% uptime with their business-class offering).
On the other hand, when something inevitably goes wrong with your on-prem system, you’ll have to deal with it. There is a laundry list of possible failures – unscheduled reboots, power failures, networking breakdowns, and overrunning your storage, just to name a few. However, some of this headache can be offset by buying a pre-built DL server that includes support. Or, given a large enough on-prem investment, it may make sense to hire a dedicated IT professional, even if part-time.
Security
While cloud providers continue to make substantial investments in security, on-prem solutions continue to be the gold standard. The obvious advantage of on-prem is that training data and models never leave the cluster. While some sectors have historically been particularly sensitive to data privacy (finance, government, healthcare), Europe’s passage of the General Data Protection Regulation (GDPR) has caused many more companies to start thinking seriously about it. Failure to do so can amount to an expensive mistake. Fines for violating the law can reach up to 4% of global revenue, with Google and Facebook having been hit with $8.8 billion in lawsuits the day GDPR went into effect.
How does Determined AI fit in?
Regardless of where you land in the cloud vs. on-prem debate, Determined’s open source platform fits into your infrastructure strategy. On the cloud side, our emphasis on fault tolerance, reproducibility, GPU autoscaling, and preemptible instance support offers you the flexibility to cost-consciously burst deep learning training workloads on the cloud. On the on-prem side, Determined decreases setup and maintenance overhead by providing deep learning-specific Docker containers for running experiments, and enables team members to seamlessly share highly sought-after GPUs.
No matter what infrastructure choice you ultimately make, your model developers will be able to leverage Determined’s deep learning experimentation capabilities: distributed training, parallel hyperparameter search based on the latest state-of-the-art early stopping methods, experiment tracking, and push-button reproducibility.
Want to learn more about how Determined can help make your deep learning organization more productive? Try it out on your infrastructure and let us know how it goes!
-
As of December 2017, Nvidia updated its end-user license agreement for its consumer grade GPU drivers (Titan and GeForce), restricting the software’s use in data centers. It is unclear what exactly constitutes a “data center,” as well as whether Nvidia will actually enforce this (they will work with customers on a “case-by-case basis”). ↩
-
This analysis found different performance for the same V100 GPU on Paperspace and Amazon EC2 due to I/O constraints. ↩
-
GPU models varied between the options for each performance tier because we were constrained by what cloud providers offer. In cases where the GPU models do not match, we chose an approximately equivalent model (by looking at peak performance, memory, and memory bandwidth). See Table 3 for more detail. Note that AWS does not have a mid-tier GPU offering. In the K80 case, prices were adjusted to account for the fact that AWS and GCP quote prices in GPUs, not by the board (K80 boards contain 2 GPUs each).
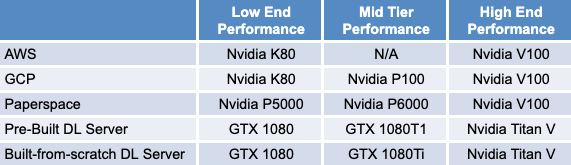
Table 3: GPU Model in Each Category -
All three public cloud providers also offer spot pricing, which allows you to bid for unused capacity. While this may seem like a great way to save money, it comes at the cost of reliability. This analysis shows that GPU spot instances are both more likely to get pre-empted and less likely to be available than general instance types. Although workarounds exist and some businesses do take advantage of this tier, it requires substantial engineering effort. For this reason, we will not focus on spot pricing in our analysis. ↩
-
The price for the pre-built DL server comes from taking the base price of the built-from-scratch server and adding 50%. This estimate comes from looking at the price difference between the pre-built server Determined AI purchased and pricing out the same components individually (although we should note the pre-built server also includes customer support). ↩