SEP 11, 2024
The Deep Learning Tool We Wish We Had In Grad School


November 05, 2020
Machine learning PhD students are in a unique position: they often need to run large-scale experiments to conduct state-of-the-art research but they don’t have the support of the platform teams that industrial ML engineers can rely on. As a result, PhD students waste countless hours writing boilerplate code, ad-hoc scripts, and hacking together infrastructure – rather than doing research. As former PhD students ourselves, we recount our hands-on experience with these challenges and explain how open-source tools like Determined would have made grad school a lot less painful.
How we conducted deep learning research in grad school
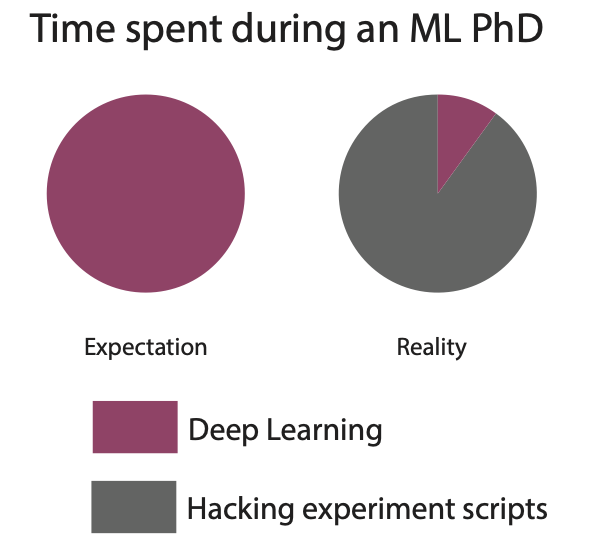
When we started graduate school as PhD students at Carnegie Mellon University (CMU), we thought the challenge laid in having novel ideas, testing hypotheses, and presenting research. Instead, the most difficult part was building out the tooling and infrastructure needed to run deep learning experiments. While industry labs like Google Brain and FAIR have teams of engineers to provide this kind of support, independent researchers and graduate students are left to manage on their own. This meant that during our PhDs, the majority of our attention was spent wrangling hundreds of models, dozens of experiments and hyperparameter searches, and a fleet of machines. Our ad-hoc workflows prevented us from doing better research, as tasks like starting new experiments and distributing training would cause increasingly more strain on the existing workflows and infrastructure.
Every project started the same, with a lone graduate student tasked with implementing a research prototype and performing a virtually endless number of experiments to test its promise. There was little infrastructure, scarce resources, and no process. So we would start writing one-off scripts: scripts to create the prototype, scripts to kick off dozens of experiments, and even more scripts to interpret the logs from these experiments. These scripts were run on whatever machines we could find: the labs’ machines, friends’ lab’s machines, AWS spot instances, or even our professors’ personal machines. As a result, we’d have gigabytes of logs in various drummed up formats, model checkpoints, and PDFs of graphs showcasing our results, scattered about the file systems of the machines we used. We quickly learned that to survive as ML graduate students, becoming well-versed in engineering, system administration, and infrastructure management was table-stakes.

The first time each of us realized that it didn’t have to be this way was when we did industry internships. As interns in a place like Google Brain, we had access to Google’s internal training infrastructure that allowed us to focus on research as opposed to operations.
It was daunting to leave a place like Google, knowing that as independent researchers, we would be back to managing our own infrastructure and that this would come at the cost of doing our research.
Fortunately, you don’t have to do grad school the way we did. Open-source tools for deep learning training have matured and can empower individual researchers to spend less time wrangling machines, managing files, and writing boilerplate code, and spend more of their time forming hypotheses, designing experiments, interpreting results, and sharing their findings with the community. But in the throes of conducting research and surviving grad school, it is difficult to invest time to learn a new tool without the guarantee that it will increase your productivity. To help future graduate students get over that hurdle, we share the ML research pain points that Determined AI would have alleviated for us.
How Determined can transform the research experience
Throughout the life cycle of a deep learning research project, you’re bound to run into several common pain points. Today, many of these can be alleviated with foresight and the right tooling. In this section, we share the pain points we commonly encountered and how tooling like Determined can help.

Monitoring experiments
A single deep learning experiment can run for days or weeks and requires constant monitoring. In grad school, we would typically monitor experiments by tailing a log file or SSH’ing into the cluster and using tmux to monitor the job’s console output. This required remembering to start the experiment in a tmux session, to log key metrics, and to manage output log file naming and organization. When running several experiments at the same time, this also required tracking which experiment was running on which machine. Tools like Determined shed this overhead by automatically tracking and persisting key metrics and by logging them to TensorBoard. These results and more are available in a web UI for users to monitor their experiments in real-time and can be shared with peers, advisors, and community members with a single link.
Dealing with failures
An experiment can also crash due to transient errors that are out of our control. This issue is exacerbated when running on preemptible cloud instances as a cost-saving measure. In these situations, we could easily lose hours or days worth of work and would then need to relaunch an experiment manually by passing a command via SSH. With Determined, the system automatically retries failed jobs for you, so no time is wasted when an error occurs. Automated experiment logging helps you diagnose and track where failures are happening across machines. Checkpoint saving also ensures that little progress is lost when a failure occurs. Determined manages checkpoints automatically: users can specify policies to control how often checkpoints are taken and which checkpoints should be preserved for future use.
Managing experiment results
The result of days and hours of experimentation are artifacts like log files, model checkpoints, and results from subsequent analyses. It’s necessary to persist results in all stages of the project to retroactively report them to the community. Initially, managing this data is straightforward to do on the file system with careful naming and folder organization. But as a project progresses, it becomes an unwieldy way to track the gigs and gigs of emerging data. For us, it was common to have to redo a long-running and resource-intensive experiment because we lost track of a particular experiment graph or the script and model checkpoint to reproduce an earlier result. Instead, it’s better to start with an experiment tracking platform early into a project’s lifecycle, so that all experiment data is managed for you. Using Determined, model source code, library dependencies, hyperparameters, and configuration settings are automatically persisted to allow you to easily reproduce an earlier experiment. The built-in model registry can be used to track your trained models and identify model versions that are promising or significant.
Distributing training
Deep learning training requires a huge amount of resources, with state-of-the-art results sometimes requiring tens of thousands of GPU hours. Almost inevitably, independent researchers need to scale their own training experiments to more than a single GPU. By relying on native PyTorch or TF distribution strategies, we were still left with tasks like setting up networking between machines and alleviating errors from machine failures and stragglers. At Determined, distributed training is rolled out for you by infrastructure experts. By writing your model code in Determined’s Trial API format, you can distribute your code with a single config file change. Determined takes care of things like provisioning machines, setting up networking, communicating between machines, efficient distributed data loading, and fault tolerance.
Managing experiment costs
Many deep learning practitioners rely on cloud platforms like AWS and GCP to run resource-heavy experiments. However, when operating within tight academic budgets, cloud platforms were often prohibitively expensive. Instead, we would run on cheaper spot instances without guaranteed uptime. Consequently, we had to manually restart stopped instances, checkpoint experiments constantly, or in absence of this, suffer lost results. To make the most use of available resources, Determined manages cloud compute resources automatically for the user depending on what jobs are queued. When using AWS spot instances or GCP preemptible instances to reduce cost, Determined maintains reproducibility with fault-tolerant checkpointing.
Hyperparameter tuning
Hyperparameter tuning is a necessary step to achieve state-of-the-art model performance. However, these were one of the most difficult experiments to run as they scale up all of the pain points previously discussed. Running a grid search is simple in theory, but ends up being orders of magnitude more costly and longer to run than traditional training. Algorithms that employ early-stopping like SHA and ASHA can be dramatically more efficient but are difficult to implement. (Well, not for Liam who invented these algorithms, but it’s difficult for the rest of us!) Hyperparameter searches also generate a lot more experimental metadata to manage and are harder to rerun when things go wrong. With Determined AI, you can run hyperparameter searches with state-of-the-art algorithms by changing a config file. And just like in regular training, you get experiment tracking, distributed training, and resource management out of the box. You can also pause, resume, or restart hyperparameter tuning jobs on-the-fly.
Ensuring reproducibility
Building upon empirical results, either by ourselves or the broader community, requires being able to reliably reproduce said results. Reproducibility is becoming a first-class goal of the ML research community, with initiatives like the Reproducibility Challenges or Artifact Evaluations. During our PhD, we found it difficult to anticipate all the data needed to ensure full reproducibility of our results. For instance, we may start by saving the experimentation script and the code (via git SHA) that led to a particular result, only to come to find that we could not reliably reproduce the result without knowing the machine the experiment ran on. With Determined AI, the data you need for reproducibility is automatically persisted for you, including the code used to create the model, the model weights, the full environment used to train the model, and the data preprocessing code.
If you are like us, you may find yourself spending most of your time on operations, not research. Fortunately, with the emergence of ML infrastructure tools, you don’t have to do ML research the way we did. Tools like Determined provide researchers the foundation to build state-of-the-art and even production grade models. If you feel like you could benefit from the backing of a training platform, we encourage you to give Determined a spin. To get started, check out our quick start guide. If you have any questions along the way, hop on our community Slack or visit our GitHub repository – we’d love to help!