Fine-Tune BERT with Determined

October 05, 2020
BERT has quickly become one of the most influential ML models in the world, leveraging the Transformer architecture to achieve state-of-the-art results on a range of natural language processing (NLP) tasks. Let’s check out how you can fine-tune BERT for your NLP task using Determined.
Getting Started Locally
Thanks to the Hugging Face transformers library, its easy to get started with BERT in Determined. The code for this example can be found here1. For the example we’ll be training a question-answering model on the Stanford Question Answering Dataset.
You can easily train a model locally – to get started clone the code above and try:
pip install -r requirements.txt
python train_local.py
This script will download SQuAD locally, download a pretrained Bert model, and begin fine-tuning on the SQuAD dataset. You’ll probably want a GPU, this could take a while!
Do More With Determined
Behind the scenes, we’ve implemented BERT in a Determined PyTorch Trial Interface. By organizing the model this way, we can use Determined to track our experiments, scale to distributed training, and do hyperparameter tuning. To get started, you’ll need to install Determined, and configure the Determined cli.
Once you have Determined running, you can train BERT and track the progress of training with:
det experiment create const.yaml .
When training has completed (about 2 epochs), your model should obtain a validation F1 score of ~88.
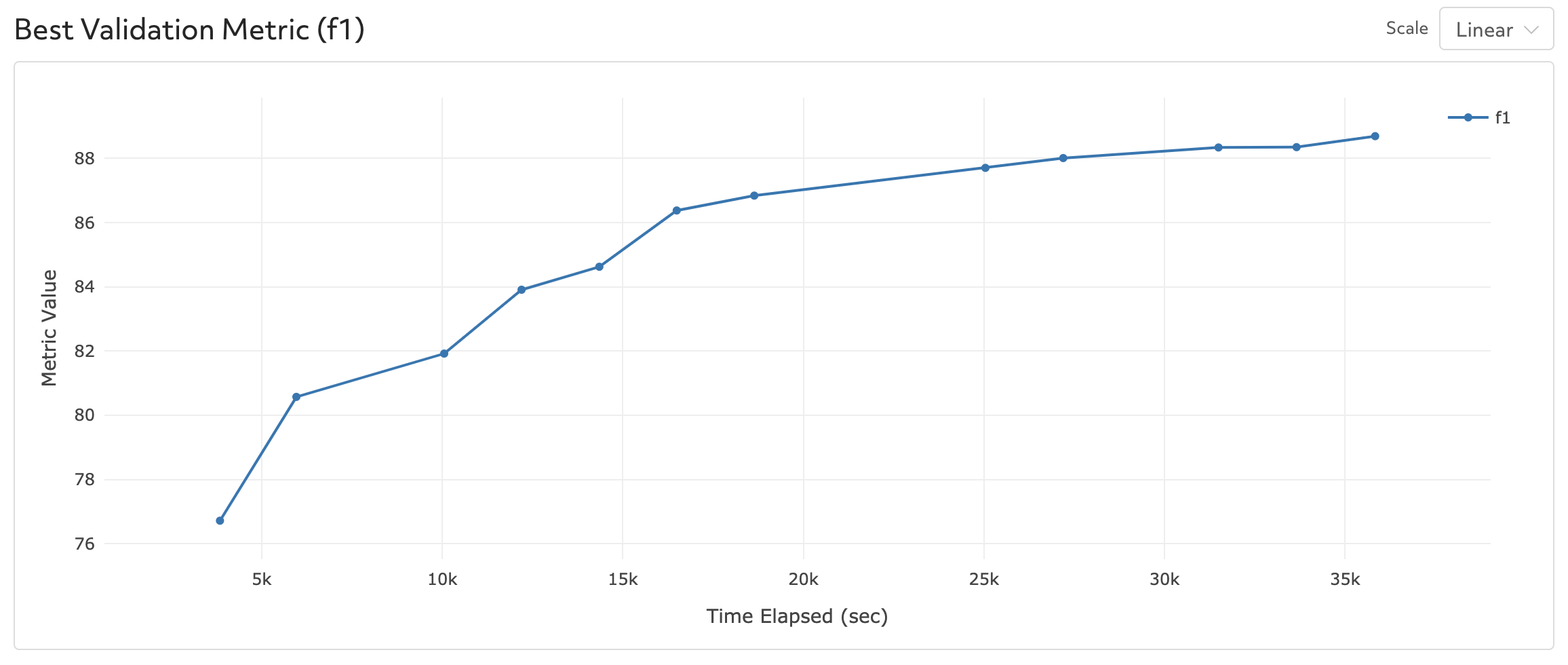
Note that the experiment we want to run is defined in const.yaml:
description: Bert_SQuAD_PyTorch
hyperparameters:
global_batch_size: 12
learning_rate: 3e-5
lr_scheduler_epoch_freq: 1
adam_epsilon: 1e-8
weight_decay: 0
num_warmup_steps: 0
max_seq_length: 384
doc_stride: 128
max_query_length: 64
n_best_size: 20
max_answer_length: 30
null_score_diff_threshold: 0.0
max_grad_norm: 1.0
num_training_steps: 15000
searcher:
name: single
metric: f1
max_length:
records: 180000
smaller_is_better: false
min_validation_period:
records: 12000
data:
pretrained_model_name: "bert-base-uncased"
download_data: False
task: "SQuAD1.1"
entrypoint: model_def:BertSQuADPyTorch
If you want to modify the experiment, say to modify hyperparameters or the duration of training, you can easily make changes to this file. For more information about how to configure experiments, check out the Determined experiment configuration documentation.
Distributed Training with BERT.
If you have a multi-GPU Determined cluster, you can run distributed training by adding a few lines to your config (captured in distributed.yaml):
resources:
slots_per_trial: 8
Which you can easily submit to Determined with:
det experiment create distributed.yaml .
To learn more about training BERT at large scales, check out this blog post.
Hyperparameter Tuning to Improve your Model
This BERT model is also outfitted for easily accessible hyperparameter tuning. To set up a hyperparameter tuning experiment, all you need to do is modify the configuration file to describe the algorithm you want to use (we recommend using ASHA) as well as the hyperparameter search space:
description: Bert_SQuAD_PyTorch_hp_search
hyperparameters:
global_batch_size: 12
learning_rate:
base: 10
maxval: -4
minval: -6
type: log
lr_scheduler_epoch_freq: 1
model_type: 'bert'
adam_epsilon:
base: 10
maxval: -6
minval: -10
type: log
weight_decay: 0
num_warmup_steps: 0
max_seq_length: 384
doc_stride: 128
max_query_length: 64
n_best_size: 20
max_answer_length: 30
null_score_diff_threshold: 0.0
max_grad_norm: 1.0
num_training_steps: 15000
searcher:
name: adaptive_asha
metric: f1
max_length:
records: 180000
max_trials: 48
smaller_is_better: false
data:
pretrained_model_name: "bert-base-uncased"
download_data: False
task: "SQuAD1.1"
entrypoint: model_def:BertSQuADPyTorch
Then launch your search with:
det experiment create search.yaml .
-
August 2023 update: The original BERT example has been replaced with an ALBERT example. ↩