SEP 11, 2024
GenAI studio is now available!

June 17, 2024
In March, we first announced GenAI Studio beta: a prompt engineering and finetuning playground. Today, we’re excited to announce the general availability of GenAI Studio! GenAI Studio is now stable, ready for production workloads, and available to all Determined Enterprise subscribers. Plus, we have released a host of new features, making GenAI Studio even more flexible. These features include:
- Guided prompt engineering with easy-to-follow navigation
- On-premises Kubernetes (k8s) deployments
- A RESTful API compatible with OpenAI standard third-party models
- Retrieval-Augmented Generation (RAG)
Let’s dive in!
1. A New Playground UI
A Wizard-like guided experience
A revamped playground UI interface makes it easy to get started with either prompt completion or RAG. Just create a new playground and choose either option from the dropdown:
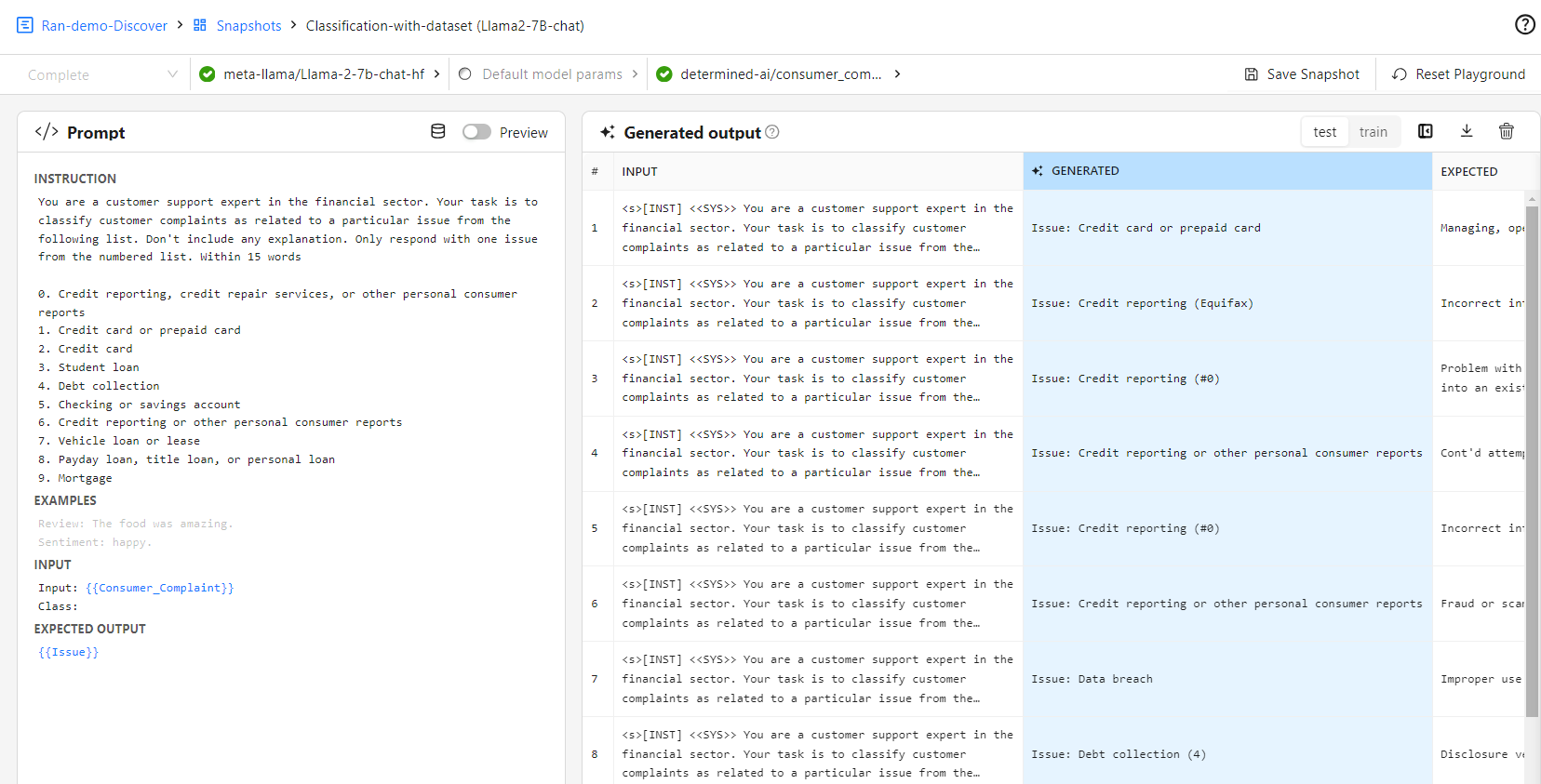
Focus on insights
Look at your generations (predictions) and expected (ground truth) side by side:
2. Support for on-prem k8s deployments
In addition to AWS deployment support, on-prem k8s deployment makes the GenAI studio experience more secure and faster. Read more in the documentation.
By deploying GenAI studio on premise via k8s, you can have full control of your data and model during the LLM workflow to ensure daa privacy and security. Also, running prompt engineering and finetuning on premise is faster than running them on the cloud, thus speeding up your prototyping process.
3. Using 3rd party models in GenAI notebooks
A new RESTful API endpoint
You can now use 3rd party models exposed through a RESTful API endpoint within a GenAI studio notebook.
What’s compatible with GenAI studio?
Any RESTful endpoint that follows the OpenAI standard. For example:
- OpenAI endpoints
- Fireworks AI
- NVIDIA NIM endpoints hosted by HPE’s MLIS.
All you have to do is call load_model_with_openai_protocol(), providing the base URL of the model, the model name, the API key, and specify the endpoint type. OpenAI supports 2 types of endpoints: chat and chat completion. Third party providers sometimes support only one or the other for a particular model.

Then, you can use the model just like any other model that is hosted on GenAI studio.

For more details, check out the docs.
Generate on datasets
Just like you can already generate model outputs on large datasets with GenAI hosted models, you can now do this with 3rd party models as well:

4. RAG
You can now build a RAG pipeline via a notebook and see the results via GenAI studio playground! This significantly speeds up the RAG development loop.
The specifics may vary, but in general, you need the following 2 things to build your RAG pipeline with GenAI studio:
1) A GenAI studio client
2) A configuration that tells GenAI studio what the RAG pipeline settings are (for example: the chat and embedding models, how to load those models, etc.)

Then, you can write your own code as usual, using GenAI studio’s helper functions, to create your vector store of dataset embeddings, and create your RAG pipeline. Some of the code to create the vector database and establish a RAG pipeline might look like the following:
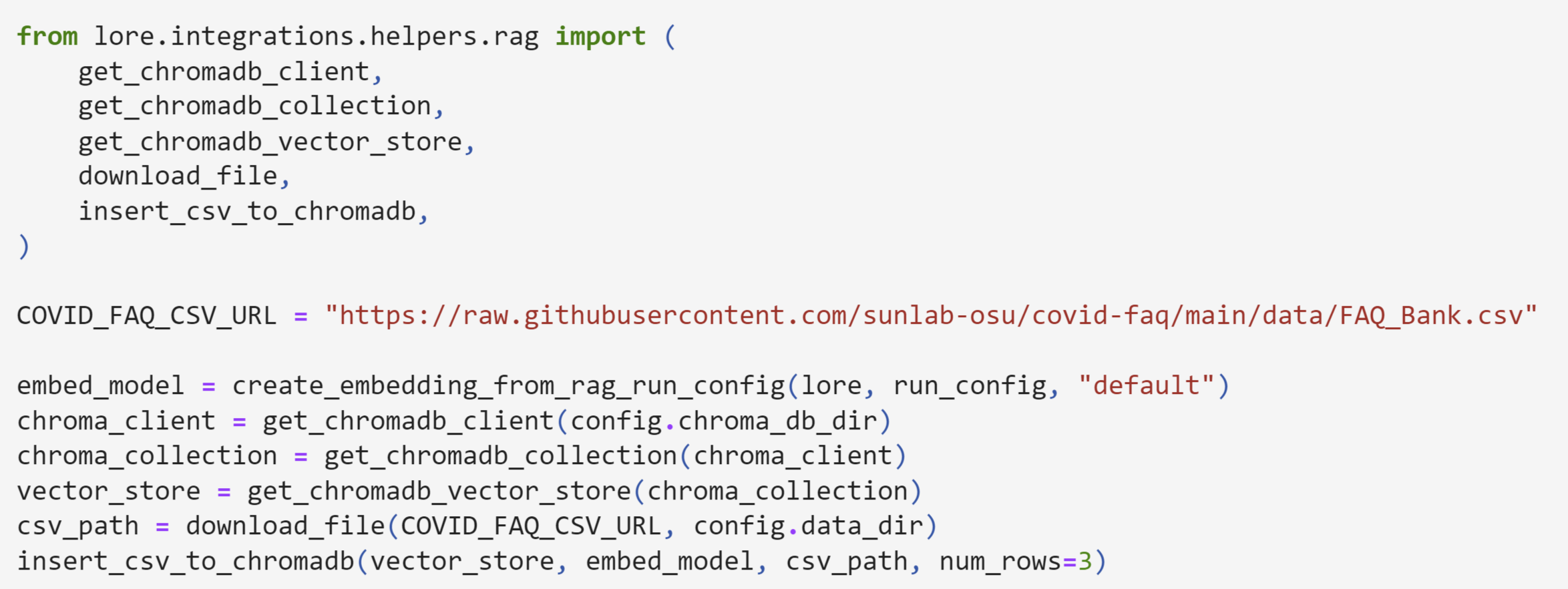

Once your RAG pipeline is created and you want to hand this off to a subject matter expert to play around with, you can do that by sending the RAG pipeline over to GenAI studio playground:

This makes our pipeline available in the playground:
You can see here that the output includes a similarity score of 0.818, which represents how similar the “Input: How is AHCCCS responding to COVID-19” is related to the section of interest.
For more details about using RAG in GenAI studio, check out the docs.
How do I get started?
Sign up for a free trial or contact us at ai-open-source@hpe.com.
Stay up to date
Stay up to date by joining our Slack Community!