SEP 11, 2024
Why Slurm Makes Deep Learning Engineers Squirm

November 13, 2020
Slurm is a cluster management and job scheduling system that is widely used for high-performance computing (HPC). We often speak with teams that are trying to use Slurm for deep learning but are running into challenges. Although it is a capable job scheduler, Slurm does not provide key features that are essential to most deep learning engineers. While it is possible to build these missing features on top of Slurm, the implementation effort and ongoing maintenance burden of doing so should not be underestimated.
What Is Slurm?
Slurm is an open-source cluster resource manager and job scheduler. Slurm is scalable and battle-tested, having been used by large companies and academic institutions on clusters with thousands of compute nodes. Slurm is a clear FOSS success story and has achieved widespread adoption — it is estimated that Slurm is used on the majority of the world’s 500 largest HPC clusters.
What Is Slurm Missing for Deep Learning?
If you’re wondering whether a deep learning training workload can run in Slurm, the answer is almost certainly yes. Slurm is designed to be flexible: if it can run on Linux, it can run in Slurm. A platform engineer may need to make the workload’s runtime (containerized or otherwise) available on the cluster, but then the model developer is off to the races wrapping their code in srun or sbatch commands, leaving the cluster resource allocation and scheduling to Slurm.
So what’s missing from this picture? Simply stated, job scheduling is only a small part of a deep learning platform. Slurm’s focus — cluster scheduling — is only the foundation of a deep learning platform. Many additional capabilities are also important:

While it is possible to build all of these on top of Slurm, for most deep learning teams the implementation (and maintenance!) effort required to do so would be massive.
Let’s look at these capabilities in four buckets, themed by benefit to the deep learning engineer:
- Better Models, Faster: tools to build more effective models more quickly.
- Tracking: automation for tracking model checkpoints, metrics, and logs.
- Scheduling and Execution: an orchestration engine that allows DL engineers to “set and forget” their training workloads without having to make their code fault-tolerant.
- User Interface and Experience: friendly interfaces that abstract away low-level infrastructure details and avoid systems integrate boilerplate, allowing DL engineers to focus on building better models.
For each, we compare implementation approaches on Slurm to Determined.
Better Models, Faster
Imagine a DL engineer who has access to a massive Slurm cluster. How would they leverage the cluster to speed up training a model? Slurm makes it simple to schedule a job on a subset of the GPUs in the cluster (via gang scheduling), but how to actually use those GPUs to speed up model training is up to the end-user. To implement distributed training with Slurm, users would need to write (or copy-and-paste) glue code that leverages their ML framework’s distributed training capabilities on top of the low-level GPU resources provided by Slurm. Or else users will need to install, configure, and integrate their model code with Horovod directly. Configuring Horovod, particularly for multi-machine training, is difficult and time-consuming for most ML engineers. Further, they will likely still need to implement training job features that are not implemented out of the box in Horovod, including gradient clipping, mixed precision, and metrics reduction. The result is a lot of wasted time, hard-to-debug model porting problems, and two separate code paths in your model code, for distributed vs. single-GPU training.
How about hyperparameter tuning? Hyperparameter tuning is key to optimizing the predictive performance of deep learning models. Because Slurm does not provide tooling for hyperparameter tuning, deep learning engineers using Slurm must either implement hyperparameter tuning themselves or integrate their model code with a specialized tool for hyperparameter tuning. Such tools come with varying degrees of integration pain, often leave performance on the table because they lag the state-of-the-art HPO methods or don’t do efficient early stopping, and typically entail DL engineers having to interact with Slurm-level APIs and concepts.1
Determined views distributed training and hyperparameter tuning as such commonplace workflows in deep learning that both are first-class natively supported capabilities. Determined offers a simple distributed training API — users simply specify the number of GPUs they want a model to be trained with, and the system takes care of provisioning, gang scheduling, the distributed training algorithm itself, and fault tolerance. Importantly, in contrast to other tools for distributed training, no model code changes are required compared to running on a single GPU. Determined centralizes distributed training logs and automatically handles fault tolerance.
The Determined team are world-experts at hyperparameter optimization; Determined employees developed Hyperband and ASHA, which are state-of-the-art methods for modern hyperparameter optimization. The Determined platform is built to support massively parallel hyperparameter tuning jobs, configured via a simple and flexible interface. As with distributed training, Determined’s support for hyperparameter tuning is unlocked with a simple configuration change — the user specifies the hyperparameter space to search over and the platform automatically handles parallelism, elastic scheduling, early stopping, metrics reporting and visualization, checkpoint management, and fault tolerance.
Tracking
What metadata do deep learning engineers need to keep track of throughout the machine learning lifecycle? The list is far different from the assets required for traditional software engineering. As deep learning engineers continually iterate, they need a lot more than GitHub and system logs to track their deliverables. The (non-exhaustive) list of items to track includes experiment metadata, training runtime environment, system and application-level logs, model checkpoints, training and validation metrics, TensorBoard event data, and random number generator state.
Slurm users must solve for all of these outside of Slurm proper or live without a standard solution in a world where each deep learning engineer implements their own one-off tracking. Experiment metadata and metrics are often tracked using a specialized tool like MLflow. Checkpoints and metrics are written by instrumenting model training code, and often stored on a distributed file system (e.g., Gluster) for Slurm on-prem or cloud object storage (e.g., GCS) if running Slurm in a cloud environment. Since tracking and storage are often managed in an ad hoc way, inconsistencies across workloads and individuals can arise.
For system and application logs, Slurm doesn’t offer centralized log management, so users or platform engineers must implement log aggregation, typically with an open-source offering like the ELK stack or a commercial product like Splunk.
Finally, Slurm’s runtime environment support is effectively as open as Linux; therefore, teams must implement and abide by a standard, whether containerized or otherwise. This freedom places the implementation onus on deep learning engineers and introduces diverse development and runtime patterns, the inconsistency of which hampers collaboration: one deep learning engineer may choose to leverage containers while another uses Conda environments directly.
Let’s face it — deep learning engineers want to spend their time on model development, not systems integration tasks like log aggregation. Determined automatically tracks experiments, metrics, and checkpoints so that data scientists can easily track their work and seamlessly collaborate with other team members. Similarly, the platform natively integrates TensorBoard within and across experiments so that users can use the tools they are accustomed to using without having to instrument their model code or worry about where to store event files.
To solve for runtime environment management, Determined makes containerization a baseline requirement for workload execution. Any task running on the system runs in one of Determined’s default container images or a custom image defined by the user. This gives teams peace of mind around the consistency and reproducibility of their deep learning workloads, without needing to implement and broadly adopt a solution or rely directly on OS-level configuration across a cluster.
Scheduling and Execution
Deep learning jobs can run for days or weeks; as such, DL engineers benefit greatly if workloads can be broken down into a series of sequential steps so that the jobs can pick up where they left off in the event of a failure or manual pause. Slurm’s model for executables is generic, so users with long-running jobs either need to make their jobs non-destructively pausable, live with losing job progress if they need to pause or preempt a job, or accept that their jobs can’t be preempted and accept the potential for cluster resource starvation that may result.2 Making a training job resumable from pause is surprisingly tricky in deep learning: when resuming training from a checkpoint, users need to ensure that model weights, hyperparameters, optimizer state, and the job’s current position in the training data set are saved and restored correctly, along with more esoteric state like random number generators. More often than not, DL engineers skirt the ability to pause and resume, resulting in undesirable behavior should they want to free up resources being used by a long-running job — the choices are to cancel the job and rerun it from scratch, or let the job continue to hold resources, resulting in Slurm workloads queueing up behind these long-running jobs that hog GPUs.
Slurm’s approach to fault tolerance is flexible and generic, but it can be hard for deep learning engineers to use. Slurm offers a protocol for fault-tolerance at the cluster management level: users can tell Slurm when nodes fail, and Slurm can tell users about observed or anticipated failures. The protocol itself doesn’t make a deep learning application fault tolerant. The pattern is analogous to Slurm’s job suspension story — Slurm offers a well-documented baseline protocol that distributed applications can use to become resilient to pauses and failures,3 but it’s up to applications to correctly implement against the protocol and actually make themselves resilient and do so efficiently.4
Determined solves for pause & resume, fault tolerance, and elastic5 workload execution automatically. We achieve this by offering an API for model code organization that allows Determined to break training workloads into smaller units behind the scenes. In the simplest case, training a model with fixed hyperparameters on a single GPU might look like this, with checkpointing and validation operations interspersed among fine-grained training sub-workloads:

If Determined hits an error during training, the platform automatically reverts to the last checkpointed state and resumes training from there:6
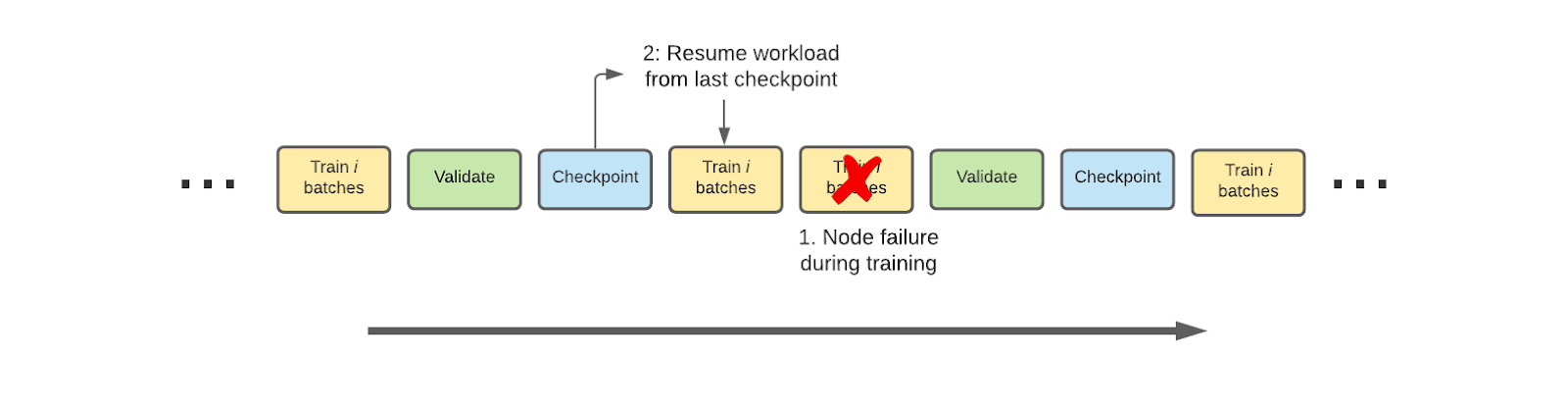
Now consider a much more intensive hyperparameter tuning workload in Determined requiring many models to be trained, and sometimes requiring coordination among models in the case of population-based training and adaptive hyperparameter tuning:
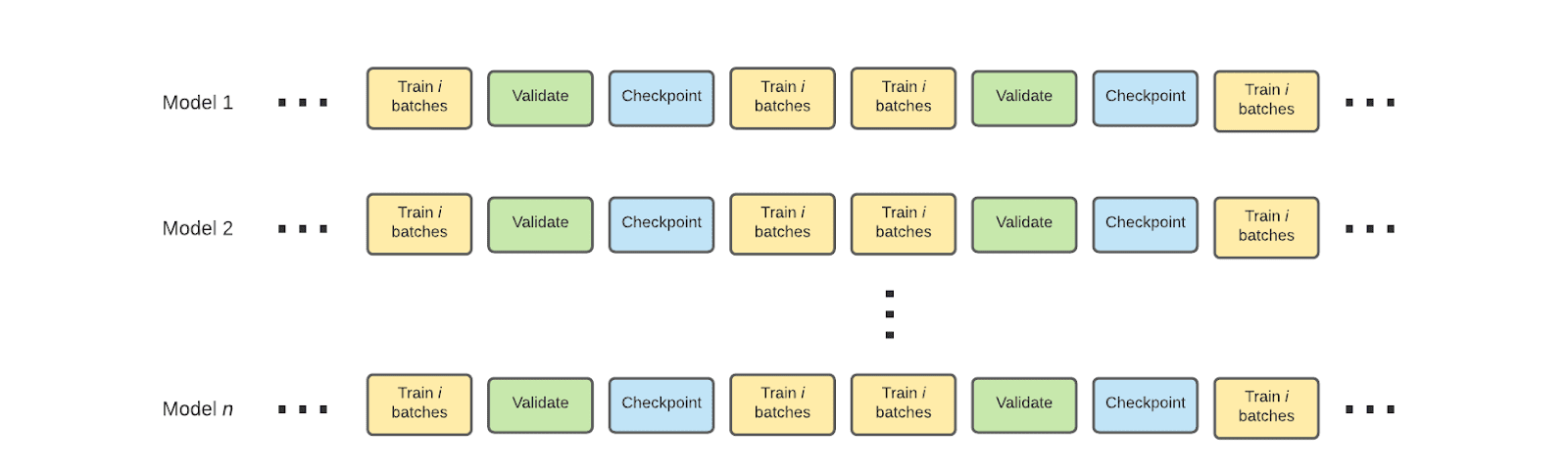
The same fine-grained workload execution model applies here. Regardless of the number of hyperparameter configurations, jobs are efficiently resilient to hiccups, whether due to unplanned failure or manual pausing. Further, this workload can complete elastically, leveraging GPUs as they come and go from the cluster, making Determined particularly well-suited to clusters in the cloud backed by lower cost preemptible or Spot instances.
User Interface and Experience
Slurm offers resource provisioning and job scheduling for any executable. To run on Slurm, deep learning engineers typically wrap Python in Slurm scripts that specify resource requirements, runtime prerequisites, and the executable to run. They then kick off the workload from a Slurm login node using Slurm CLI commands like sbatch.
Deep learning on Slurm will look very different depending on the ML library used. Assuming an organization already has a Slurm cluster, PyTorch Lightning offers facilities to lighten the burden of training on Slurm,7 but there is no asset tracking, users have to manage conda across daemon nodes, and users still need to interact directly with Slurm, or indirectly via a Python wrapper that still exposes Slurm concepts directly to the data scientists. The interface for TensorFlow on Slurm is less feature full, providing a mechanism for distributed training but no solution for hyperparameter tuning.
In contrast, Determined offers a clean and consistent API for defining TensorFlow and PyTorch training workloads, yielding standardized and more maintainable model definitions across deep learning teams. Determined’s high-level API for workload submission abstracts away the underlying resource provider and scheduler. This results in a simpler user experience for deep learning engineers and avoids the need to learn a cluster scheduling tool and express workloads in terms of low-level scheduling constructs. Determined offers intuitive knobs and sane defaults for resource utilization, like the degree of parallelism that training and hyperparameter tuning workloads can exploit.
Final Thoughts
Slurm provides battle-tested tooling for orchestrating distributed workloads submitted by potentially large teams; however, by design, it doesn’t solve for a large class of deep learning needs. To provide key deep learning capabilities such as distributed training, hyperparameter tuning, fault tolerance, reproducibility, and experiment tracking, organizations will need to build substantial internal infrastructure on top of Slurm. Unless your team has already invested heavily in building these DL capabilities on Slurm, the path to providing an efficient and complete DL platform will be long and steep, with the user experience highly prone to becoming disjointed at every turn.
We encourage you to try out Determined’s integrated platform approach to curing the systems pains that deep learning engineers face. We are proudly open source and easy to install anywhere: on-prem, in the cloud, on Kubernetes, or on your laptop. Check us out on Github, join our Slack community, give our quickstart a shot, and let me know how it goes!
Notes
-
For example, see here for a Ray user’s recent experience in attempting to run on Slurm, and here for a view into PyTorch Lightning’s hyperparameter tuning on Slurm, the last of which only offers random and grid search, both of which fall well short of SOTA early stopping-based methods for deep learning. ↩
-
Slurm’s suspend and resume operations only go as far as sending signals; the hard part of actually making a training workload pausable and resumable is up to the deep learning engineer: “User processes must stop on receipt of SIGSTOP signal and resume upon receipt of SIGCONT for this operation to be effective” ↩
-
See
scontroldocumentation here, particularly around signal handling: “User processes must stop on receipt of SIGSTOP signal and resume upon receipt of SIGCONT for this operation to be effective.” ↩ -
A job that restarts from scratch on failure might be considered resilient to the failure, but certainly not efficient in its recovery. ↩
-
Start a hyperparameter tuning workload with 4 GPUs available and the platform might use all 4. Add 16 more GPUs to the cluster and the same workload will dynamically leverage the newly added GPUs without user intervention. ↩
-
This behavior can be disabled by setting
max_restartsto zero in the experiment configuration. ↩ -
See examples here for hyperparameter optimization and here for training. ↩