SEP 11, 2024
MESA and Co-Designing Model Architectures with Hardware

February 05, 2024
Here’s what caught our eye last week in AI.
MESA
Feature matching is the process of finding points in one image that correspond to points in another image of the same scene. It’s a challenging task since the two images can be taken at very different angles and times. This new paper proposes MESA (Matching Everything by Segmenting Anything), which is a method that first finds matching areas with the help of the Segment Anything Model (SAM), and then finds matching points within each area using existing feature matching techniques.
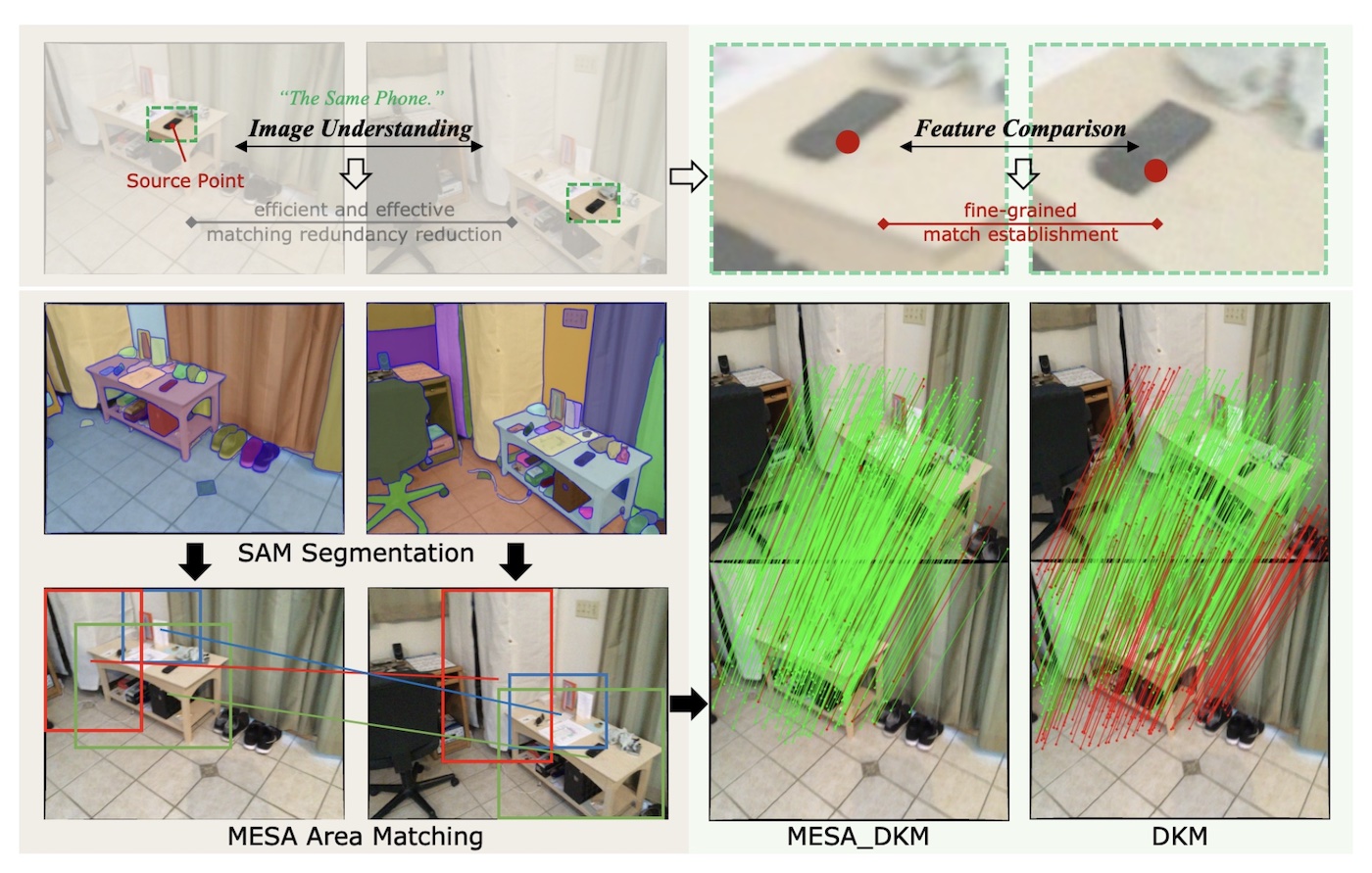
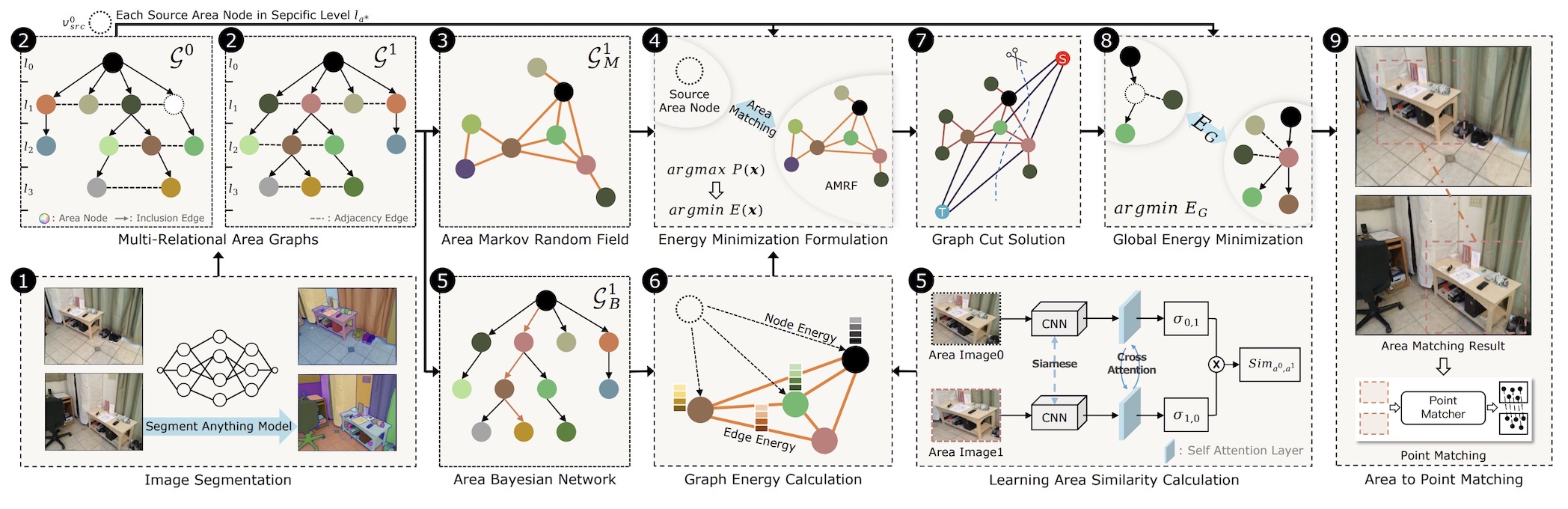
The authors suggest that it is necessary to process the outputs of SAM with graphical models as shown below, instead of using the outputs directly.
Co-Designing Model Architectures with Hardware
Deep learning model architectures can be optimized to run faster on specific hardware. This paper investigates the performance of General Matrix Multiplications (GEMMs) in transformer models during training and inference, on NVIDIA GPUs. Why focus on GEMMs? Because according to the authors, GEMMs make up most of the computations in transformers (68% to 94% depending on model size). The authors point out several characteristics of NVIDIA GPUs that can slow down performance, like tile quantization and wave quantization, and suggest a number of rules for creating efficient transformer models. Applying these rules to the GPT architecture results in speed gains of up to 39% while maintaining the same accuracy.



New Models, Datasets, and Benchmarks
- Olmo: A 7 billion parameter LLM. The model, code, and training data are all open-source.
- Dolma: A 3-trillion token dataset used to train Olmo-7B, plus a toolkit for processing text data.
- Nomic Embed: A text-embedding model. The model, code, and training data (235 million text pairs) are all open-source.
- WhisperSpeech: A text-to-speech model built with the help of the Whisper speech-to-text model.
- TravelPlanner: A benchmark to evaluate an LLM’s ability to plan with constraints.
Other news
- MobileDiffusion: Sub-second 512x512 image generation on mobile devices.

- Robust Prompt Optimization: Prevents LLM jailbreaking by appending a suffix to user prompts.
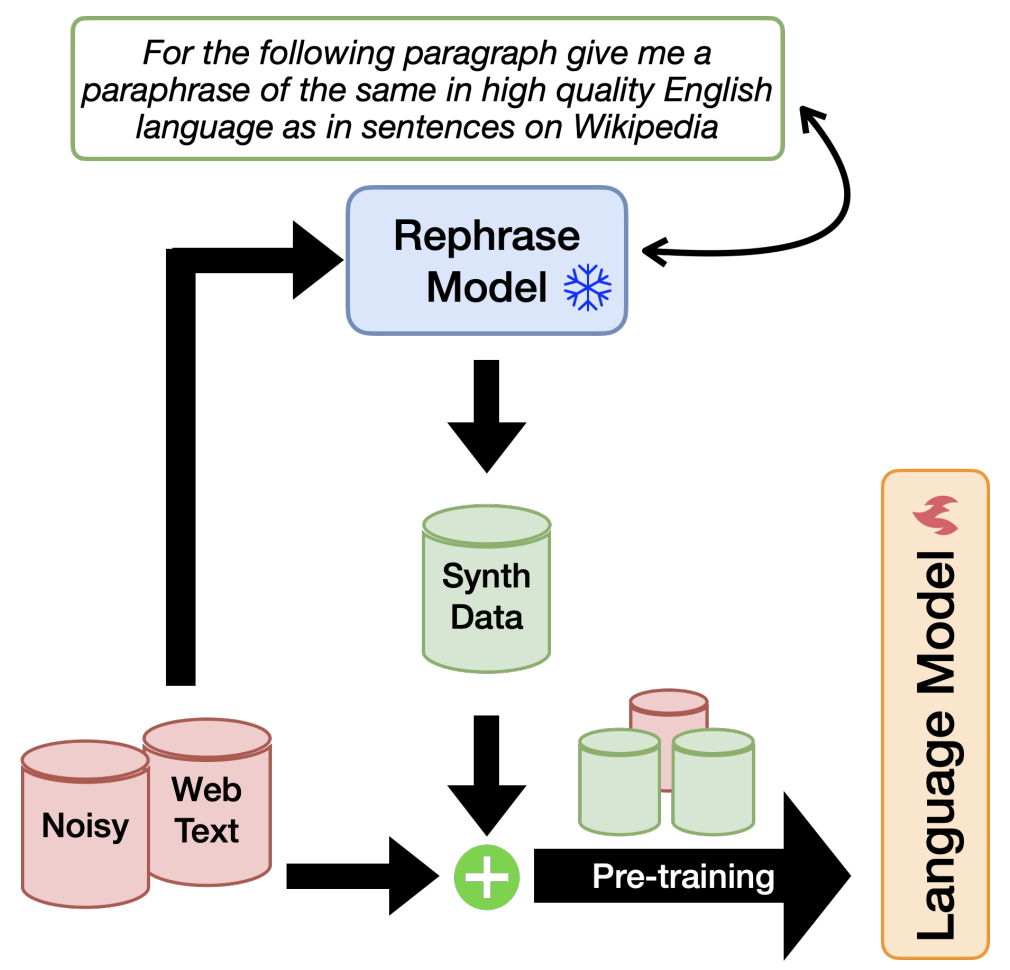
- Rephrasing the Web: Pretrain LLMs on both real and synthetic data, where the synthetic data is created by another LLM that rephrases real data in a specified style.
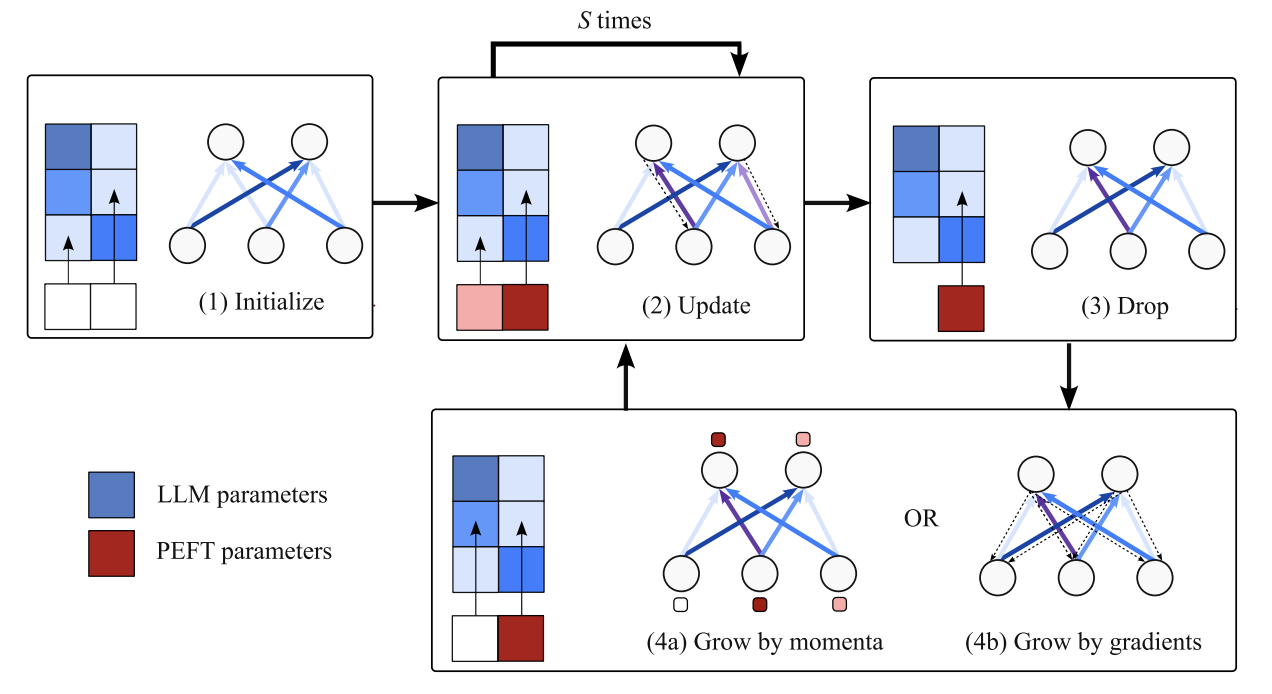
- SpIEL: A sparse fine-tuning method that is “often superior to popular parameter-efficient fine-tuning methods like LoRA in terms of performance and comparable in terms of run time”.
Stay up to date
Interested in future weekly updates? Stay up to date by joining our Slack Community!