SEP 11, 2024
1-bit LLMs, Talking Head Generation, and ChatMusician

March 03, 2024
Here’s what caught our eye last week:
BitNet: 1.58-bit LLMs
1-bit LLMs are a cutting edge approach that slashes LLM energy requirements without sacrificing model performance. This research is highly important because LLMs today eat up a TON of compute when it comes to training, finetuning, and deploying. Here’s a breakdown of how this works and what being “1-bit” actually means:
What Does “1-bit” Mean?
In traditional neural networks, parameters (or weights) are often stored in 32-bit floating-point format (FP32), or in some cases, in 16-bit floating-point format (FP16) to reduce memory and computation requirements. Each parameter in these formats requires 32 or 16 bits of memory, respectively.
A “1-bit” model, on the other hand, represents each weight with only one bit of information, typically indicating two possible values (e.g., -1 and 1). The BitNet b1.58 goes a bit further by using a ternary system {-1, 0, 1}, effectively requiring slightly more than 1 bit per parameter, hence the name b1.58. For simplicity, the approach is broadly categorized under the umbrella of “1-bit” models.
1-bit models allow for:
- Storing larger models in the same amount of memory
- Lower latency
- Increased throughput
- Reduced energy consumption
Since 1-bit model performance is on par with full-precision Transformer LLMs, including perplexity and end-task performance, along with significant energy reductions, this also means that BitNet enables a new scaling law:
A “scaling law” refers to a pattern that describes how the performance of a model changes with respect to certain factors like size, or the amount of training data and compute resources. Scaling laws predict how much improvement in model performance (such as accuracy or perplexity) one can expect when resources are increased. In essence, the new scaling law provided by BitNet b1.58 suggests that you can have larger and more powerful models with much lower additional costs than previously understood. Take a look at the comparisons between different BitNet sizes and corresponding FP16 LLMs:
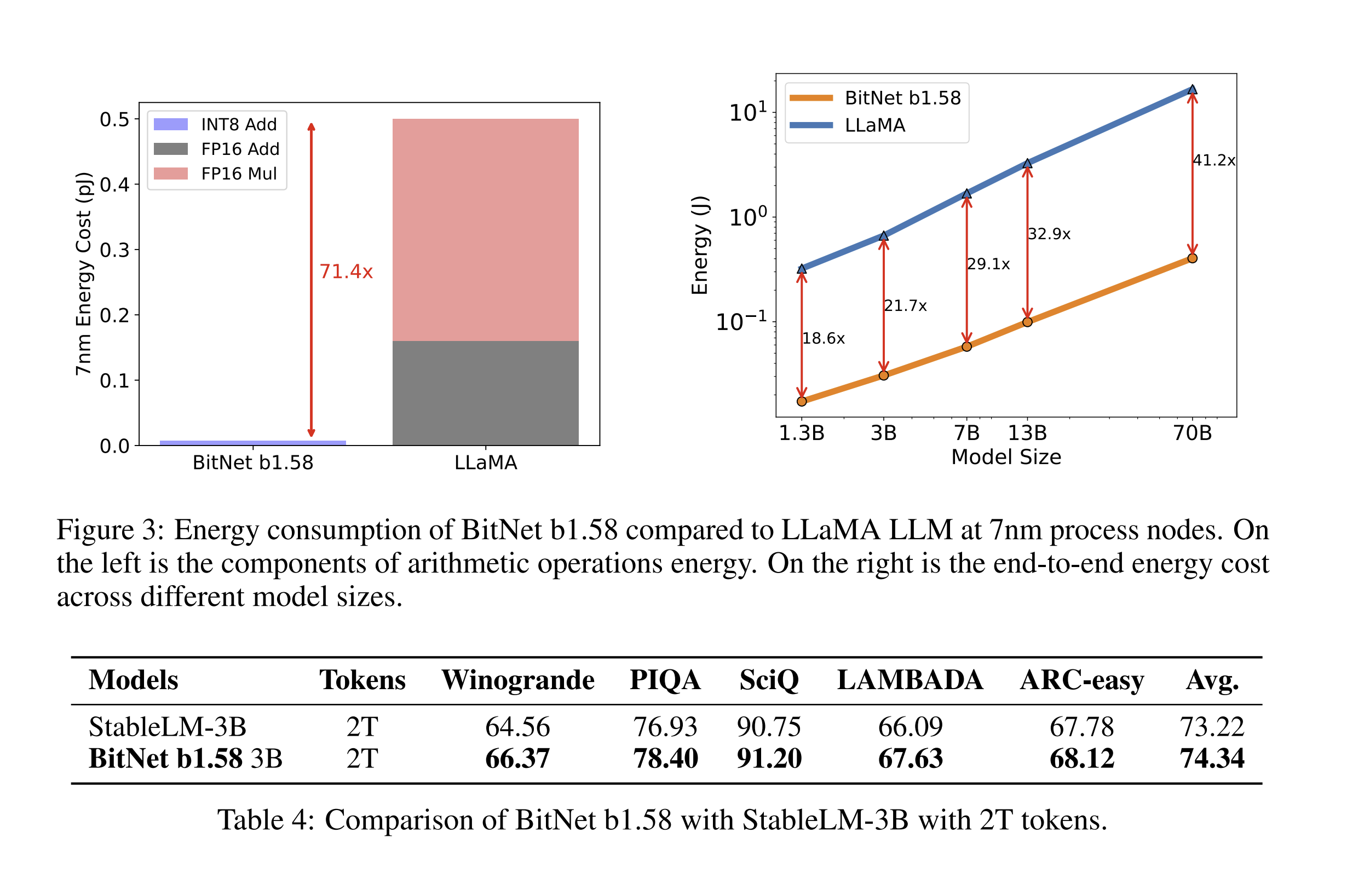
The caveat right now is that these 1-bit LLMs require specialized hardware to realize their full efficiency potential, so there’s still some work to be done before these revolutionize the AI space.
EMO: Emote Portrait Alive
EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions - is a new method for “talking head” generation from audio, and it works extremely well.
What exactly does “talking head” generation mean? Given an audio and an input image, generate an animated video of that image (a “talking head”) that matches the input image and speaks the input audio. See the image below for illustration:
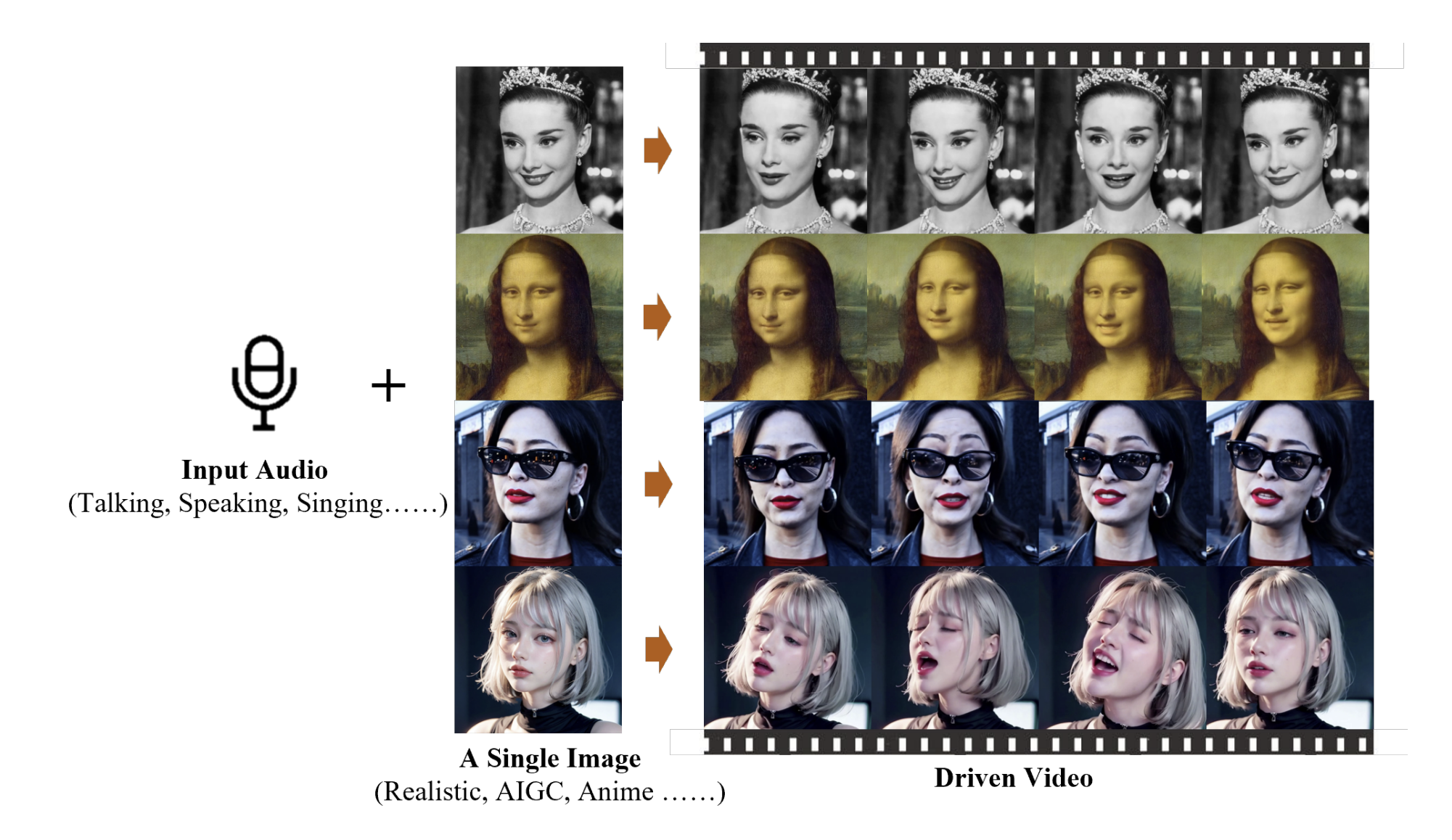
Existing work on talking head generation is limited in certain ways - for example, restricting head movements to those seen in a source video, or restricting facial keypoints. These restrictions result in videos that don’t nearly capture the full spectrum of human head movements and micro-expressions. The goal behind EMO is to create a novel framework for talking head generation that results in highly expressive, realistic videos.
The researchers exploit the fact that facial cues are hidden in audio signals, and directly train an audio-video model on a vast set of audio-video data. By itself, this leads to jittery and distorted output. However, after applying a series of stabilizing mechanisms, including a speed and facial region controller, as well as a character-preserving identity module called FrameEncoding (based off of ReferenceNet), the authors succeed in creating this audio-video generation model that outperforms SOTA models on relevant benchmarks. Read more in the paper and check out some of the results here.
ChatMusician: Understanding and Generating Music Intrinsically with LLM
Yep, that’s right - Transformers can generate music now too.
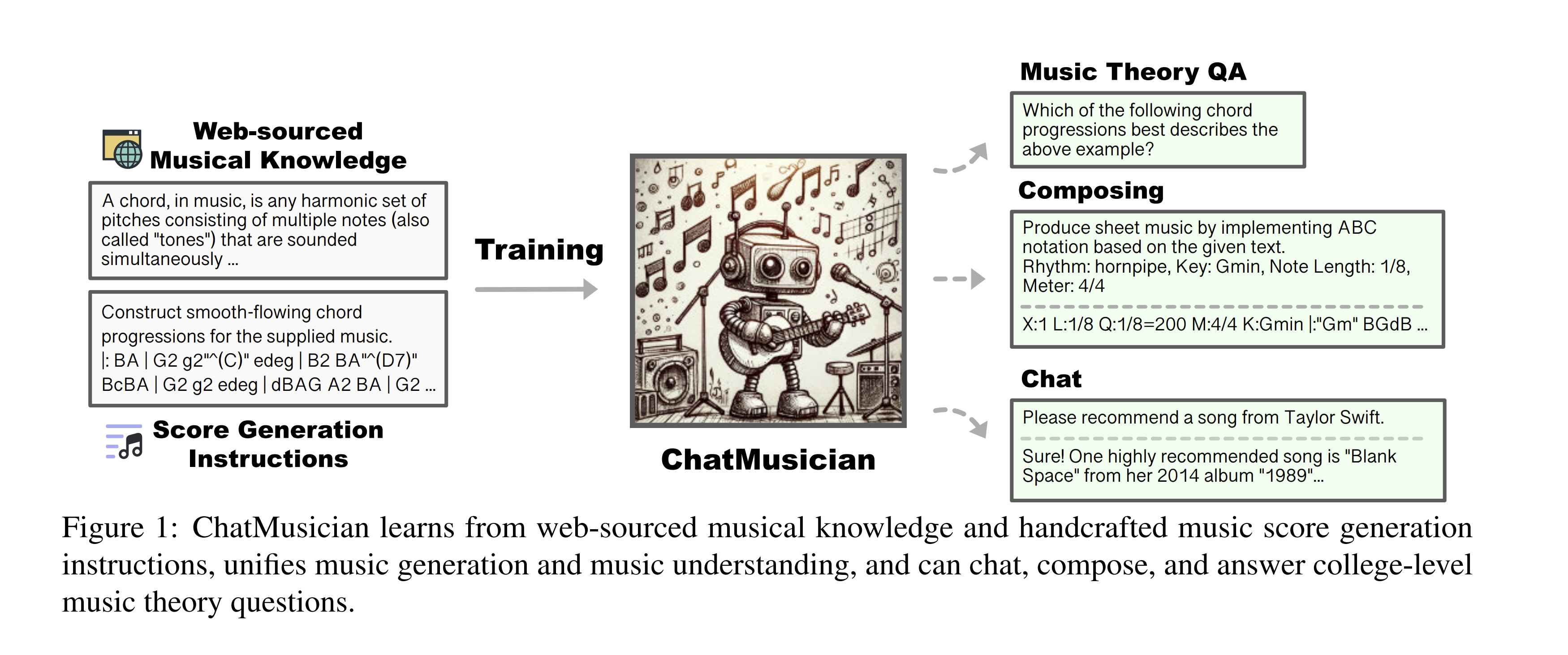
ChatMusician is a novel open-source Large Language Model (LLM) specifically developed to understand and generate music intrinsically. Unlike other models that require specialized structures for multi-modal processing, ChatMusician can interpret and create music using a standard text tokenizer, thanks to its training on a text-compatible music representation known as ABC notation. The model treats music as a “second language,” enabling it to generate musical compositions directly from text prompts. Check out the diagram from the paper below:
The introduction of musical abilities to the model does not degrade its language performance; in fact, it even shows a slight improvement in language understanding based on MMLU score.
ChatMusician can create full-length musical pieces that can be conditioned on various musical elements such as text descriptions, chords, melodies, motifs, and musical forms.
The research team has also released a significant 4 billion token music-language dataset called MusicPile, the MusicTheoryBench benchmark, and all related code and models on GitHub.
Interested in future weekly updates? Stay up to date by joining our Slack Community!