SEP 11, 2024
Emu Video, LLM Decontaminator, Faster SAM, and a Genome LLM Review Paper

November 20, 2023
Here’s what caught our eye last week in AI.
1) Emu Video and Emu Edit
The GenAI team at Meta has released two new papers: Emu Video and Emu Edit.
Emu Video
Emu Video is a text-to-video model that runs in two-steps:
- Generate a single image from the input text, using a diffusion model
F. - Generate the next frames using the same model
Fconditioned on both the first frame and the input text.

The diffusion model is a pretrained text-to-image model, with additional 1D convolution and attention layers to allow processing of a temporal dimension (see the Make-a-Video paper for details). It’s finetuned on text-to-video data, during which it is tasked with predicting future frames, given a starting frame and the input text. When combined with a temporal interpolation model, Emu Video can create 4-second long 16 fps videos, at a resolution of 512x512. You can see some samples here.
Emu Edit
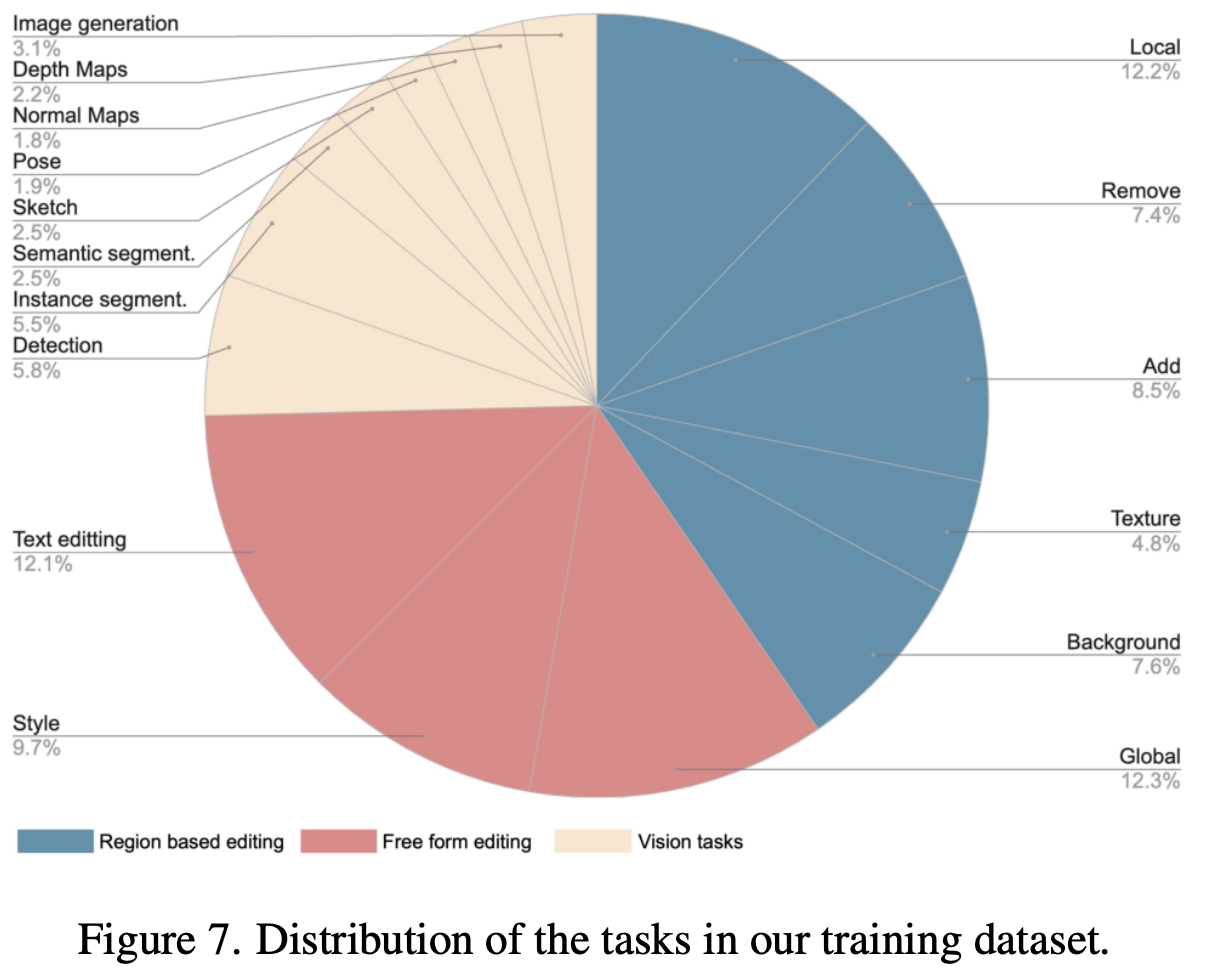
Emu Edit is a diffusion model that can perform a variety of image-editing and computer-vision tasks. It is trained on a new dataset consisting of tasks like:
- Region-based editing, e.g. substituting, removing, and adding objects
- Freeform editing, e.g. changing the style of the image
- Vision tasks, e.g. object detection, segmentation
To create the dataset, they leveraged the Llama2 LLM and the DINO self-supervised vision model. For example:
- Llama2-70b to generate editing instructions, a caption for the ideal output image, and a list of objects that should be added or updated to the original image.
- DINO to generate masks for region-based editing tasks.
See the appendix of the paper for full details.
You can see some sample image edits here.
2) LLM Decontaminator
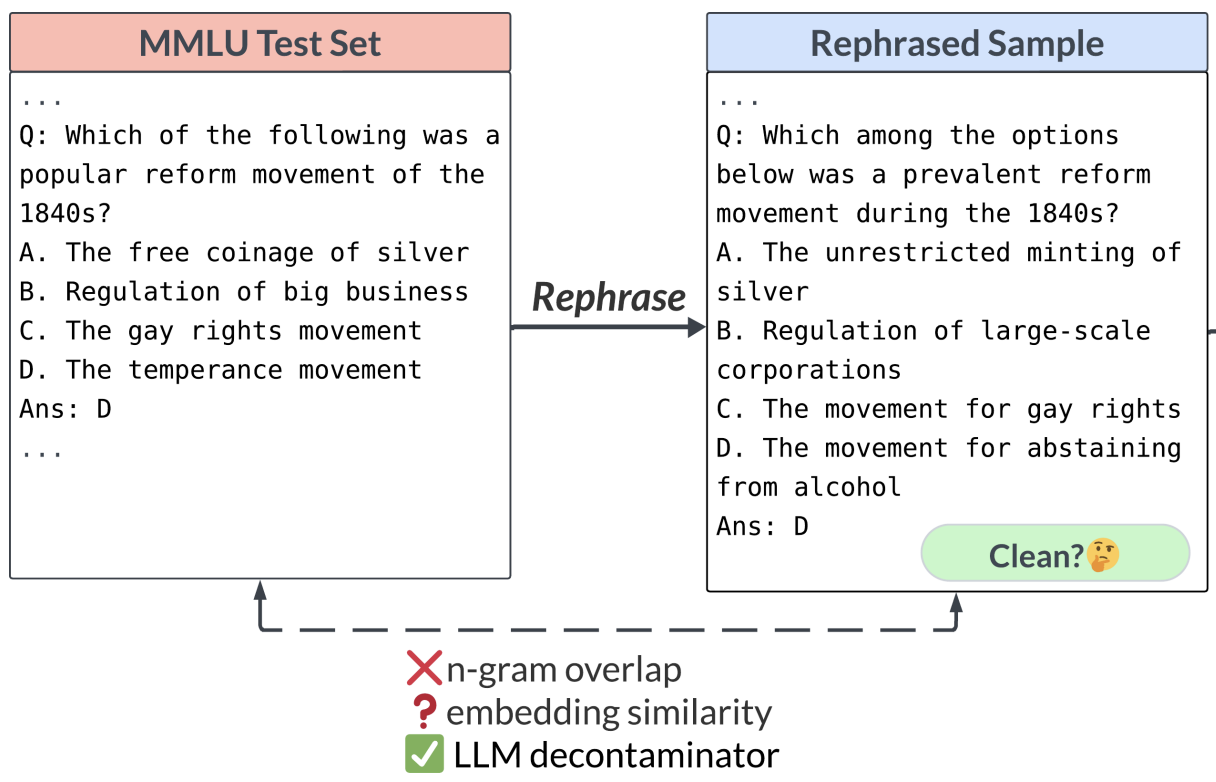
Training data contamination is the problem of test set data existing in the training set. To properly evaluate the generalization capabilities of LLMs, it is important to have a reliable method for detecting training data contamination. But this turns out to be a difficult problem. A new paper (Rethinking Benchmark and Contamination for Language Models with Rephrased Samples) introduces the following contamination detection technique:
- Given a test set sample, find the most similar training set samples, using k-nearest-neighbor search in the embedding space.
- For each training set sample, ask an LLM like GPT-4 to return True if the training sample is a rephrased version of the test sample.
They find that this approach outperforms other contamination detection methods like n-gram overlap and embedding similarity.
3) Faster models using new PyTorch features
A new PyTorch blog post highlights how the Segment Anything Model (SAM) can be accelerated up to 8 times using new PyTorch features: torch.compile, GPU quantization, Scaled Dot Product Attention, Semi-Structured Sparsity, NestedTensor, and a custom Triton kernel. See the details here.
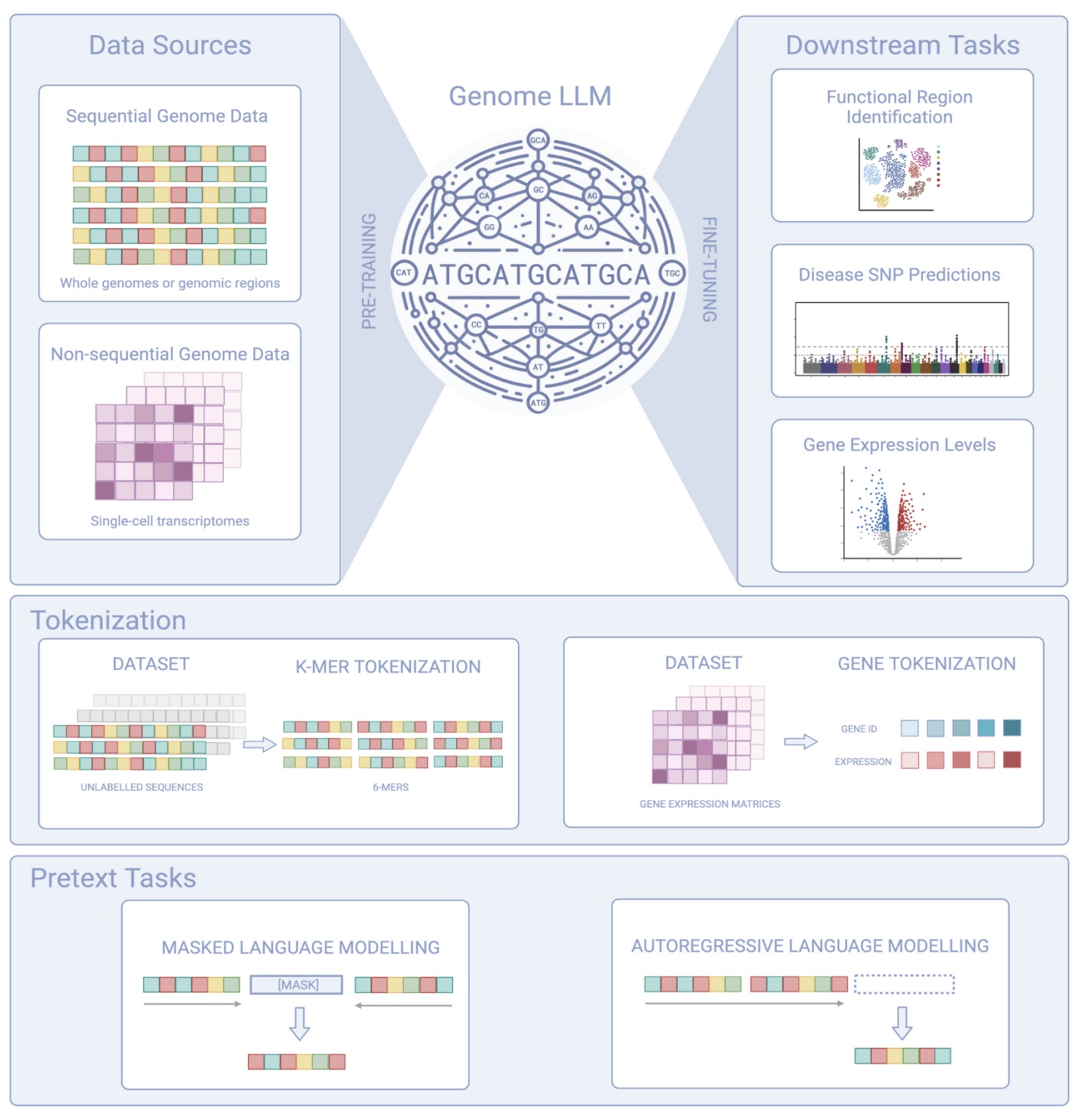
4) A Review of Genome LLMs
Language models are not just for language processing; they’re being used to analyze genome data too. A new paper reviews how these models are applied to genome data for tasks like disease risk prediction. Check out the paper: To Transformers and Beyond: Large Language Models for the Genome.
Stay up to date
Interested in future weekly updates? Stay up to date by joining our Slack Community!