SEP 11, 2024
Visual Anagrams, Adversarial Diffusion Distillation, and A New Multi Modal Benchmark

December 04, 2023
Here’s what caught our eye last week in AI.
1) Visual Anagrams
This new paper uses a diffusion model to create optical illusions where an image appears to show different content depending on the perspective or applied transformation. For example, the image on the left looks like an old woman, but when flipped upside down, it looks like a dress:

The algorithm is best explained by Figure 2 from the paper (see below). It employs a pretrained pixel diffusion model, requiring no further finetuning or datasets.
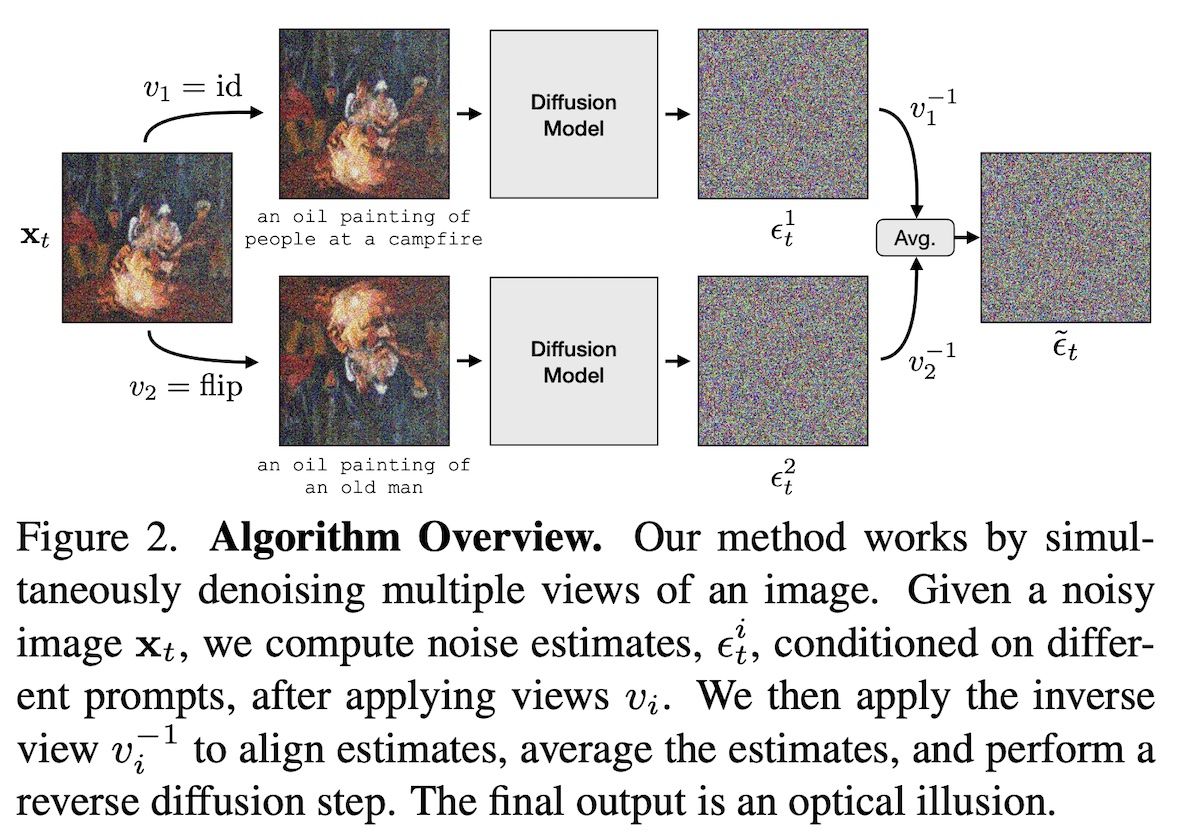
A previous similar project focuses solely on rotations, whereas the new algorithm accommodates a broader range of transformations, including skews, color inversions, and jigsaw rearrangements. Another similar project works with many transformations, but has lower quality results.
You can generate your own visual anagrams with the code available on GitHub.
See some amazing examples at this link.
2) Adversarial Diffusion Distillation
Diffusion models can be slow due to their multi-step denoising process. A new training method called Adversarial Diffusion Distillation reduces the multi-step process down to a single-step, resulting in significantly faster inference. This method integrates concepts from diffusion models, GANs, and model distillation. Essentially, the one-step diffusion model is trained to output images that fool a discriminator (this is the adversarial part similar to GANs), while also matching the output of a multi-step diffusion model (this is the distillation part).

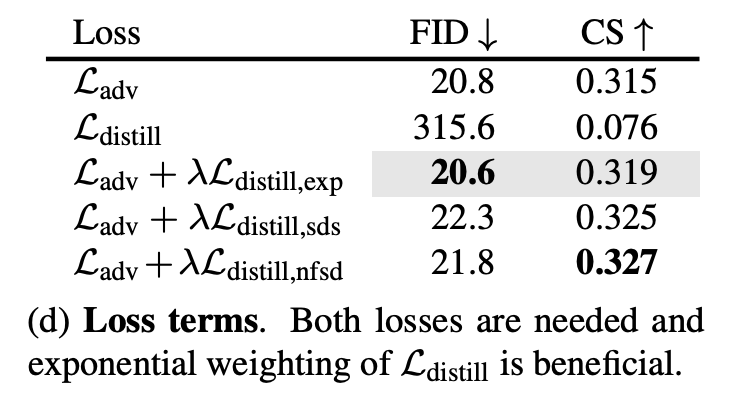
Based on an ablation study from the paper, it appears that adversarial training works quite well on its own, and distillation boosts results slightly. The table shows that the Ladv loss alone gets similar FID and CS scores as using the Ladv + Ldistill losses.
SDXL-Turbo is a model trained using this method, and it’s available for download at this link.
3) A New Multi Modal Benchmark
There’s a new benchmark for evaluating large multi-modal models, called the Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark, or “MMMU”. It comprises 11,500 questions containing both images and text. GPT4 scores 56%, so it’s a difficult benchmark (for now). Here’s a figure from the paper showing some examples:

4) And More…
- Ask ChatGPT to repeat a word over and over and it’ll eventually start spewing out training data. See the full explanation here.

- Visualize how an LLM works in this amazing interactive webpage (screenshot below).
Stay up to date
Interested in future weekly updates? Stay up to date by joining our Slack Community!