SEP 11, 2024
Mobile ALOHA, AppAgent, Virtual Token Counter, and Time Vectors

January 08, 2024
Here’s what caught our eye in the past few weeks in AI.
Mobile ALOHA
ALOHA is “A Low-cost Open-source Hardware System for Bimanual Teleoperation” that was presented in April of last year. It’s a robot that learns from demonstrations, which are performed by a human via teleoperation of its arms.
Mobile ALOHA is ALOHA mounted on a mobile base. It too learns from demonstrations, but the human teleoperates the mobile base in addition to the arms.
After training, the robot can autonomously perform tasks that require high dexterity, like lifting a wine glass and cleaning the spilled wine underneath it. See the project webpage for video demos, and links to the open-source code.
AppAgent
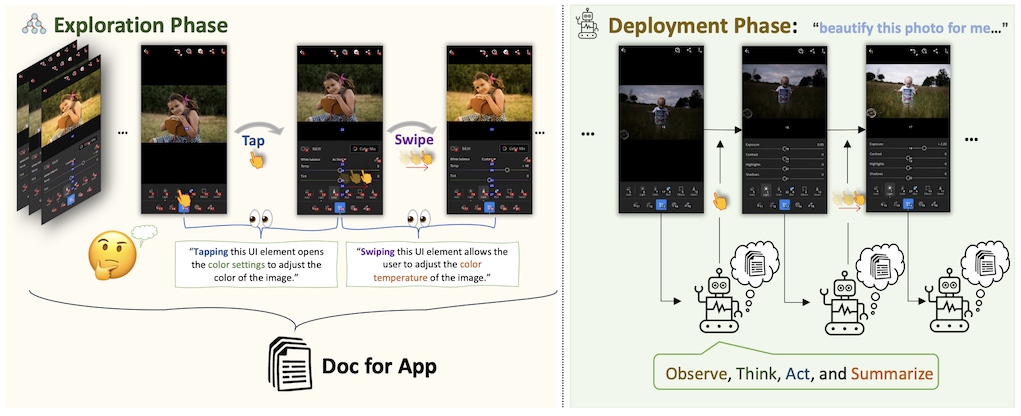
AppAgent is a framework that enables a Multimodal LLM to use smartphone apps. To simplify the problem, the LLM is given access to a limited number of functions:
- Tapping and long-pressing elements.
- Swiping elements with a specific direction and magnitude.
- Writing text in an input field.
- Going back, or exiting.
There are two phases in the AppAgent framework. In the “exploration” phase, the LLM is given a task to complete, and works towards this task through trial and error. Each time the LLM performs an action (via one of the above functions), it receives a screenshot of the app, analyzes it, and records the action-effect pair in a reference document. Note that this phase simply produces a reference document, and does not change the weights of the model (which in this case is GPT-4).
In the “deployment” phase, the LLM is once again given a task to complete. But now it is able to refer to the document that was compiled in the exploration phase. This helps it select actions in a more intelligent way.
See the project webpage for some video demos.
Virtual Token Counter
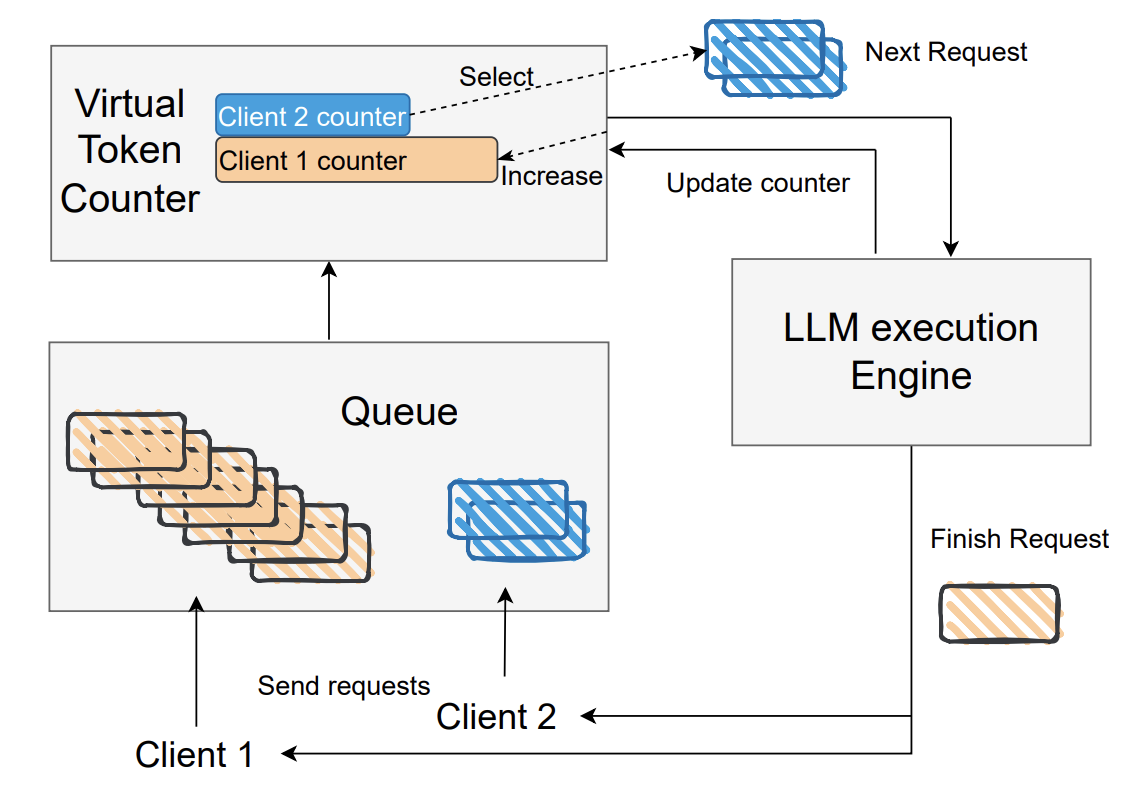
Products like ChatGPT limit each user to a certain number of messages per hour. This is done to ensure that all users can have a reasonable level of access, without overloading the servers. But is this the optimal approach? A new paper presents an alternative called Virtual Token Counter (VTC). In a nutshell, VTC continuously updates a record of each client’s usage of tokens or FLOPs, and prioritizes requests from clients with lower usage. An open-source implementation of the algorithm is available on GitHub.
Time Vectors
Is the difference between 2012 text and 2016 text encoded in the weights of an LLM? This paper suggests the answer is yes, with the concept of time vectors.
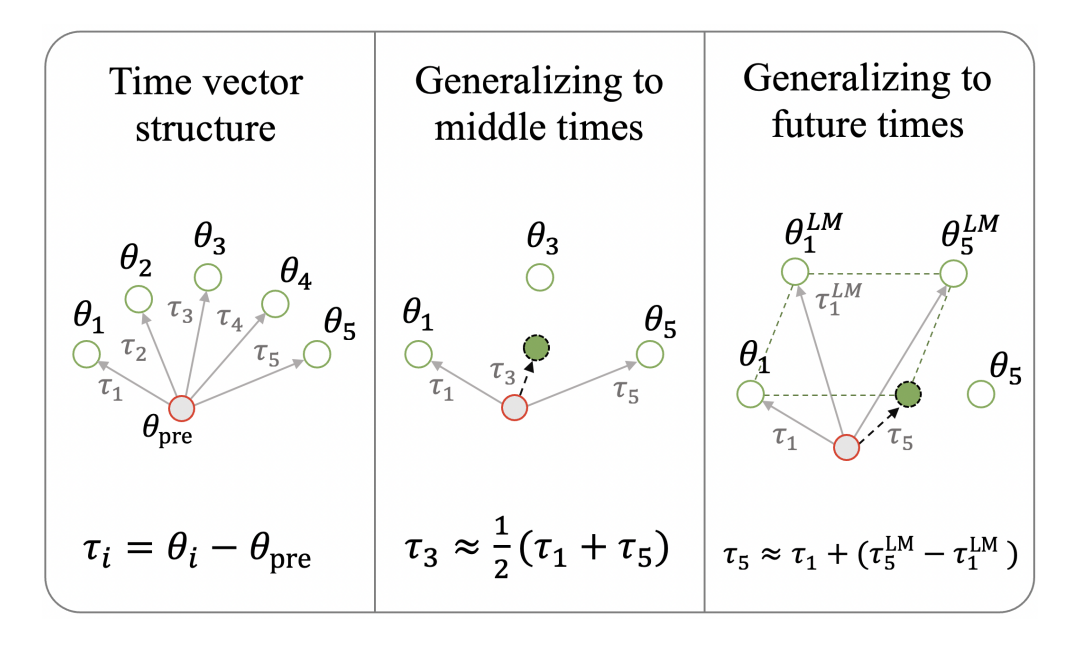
A time vector is obtained by finetuning a model on text from a specific time period, and then subtracting the pretrained model weights from the finetuned model weights. The authors call this a time vector because it’s the direction that the pretrained model weights have to “move” in order to perform well in the specific time period.
Therefore, if you have a time vector for both 2012 and 2016, you can obtain a 2014 time vector via interpolation. Adding the 2014 time vector to the pretrained weights results in a model that makes better predictions on 2014 text. See figure 5 in the paper for related experiment results.
Newly Open-Sourced Models
- TinyLlama: a “1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs.”
- Ferret: a 7B Multimodal LLM that can answer questions about images at a granular level.
And More…
-
Improving Text Embeddings with Large Language Models: Trains an embedding model using contrastive learning on a dataset of query/document pairs generated by GPT-4.
-
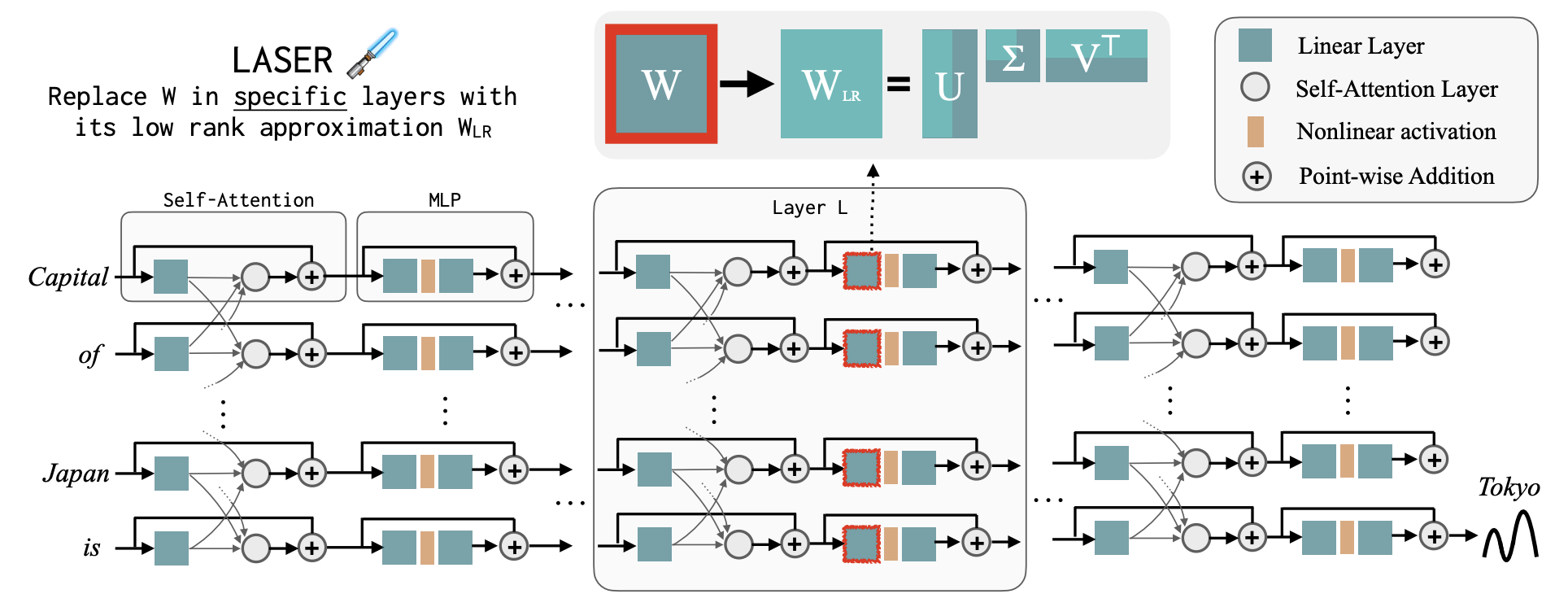
Layer-selective rank reduction: Improves accuracy by replacing specific layers of an LLM with their low-rank approximation.
-
Composition to Augment Language Models: Combines the capabilities of two models, using cross-attention.
-
Principled Instructions Are All You Need: An empirical study of prompt engineering. Includes a handy table of 26 prompting principles (see table 1 in the paper).
Stay up to date
Interested in future weekly updates? Stay up to date by joining our Slack Community!