SEP 11, 2024
Unsloth, V-star, and TOFU

January 12, 2024
Here’s what caught our eye last week in AI.
Unsloth
Unsloth is an open source library developed to make finetuning LLMs a LOT faster. It’s built to work with the Hugging Face ecosystem (which means you can use it with Determined too - check out our HF Trainer examples). With Unsloth, training Llama models is almost 2 times faster. Read more about it in their blog post.

V*: A new visual search method
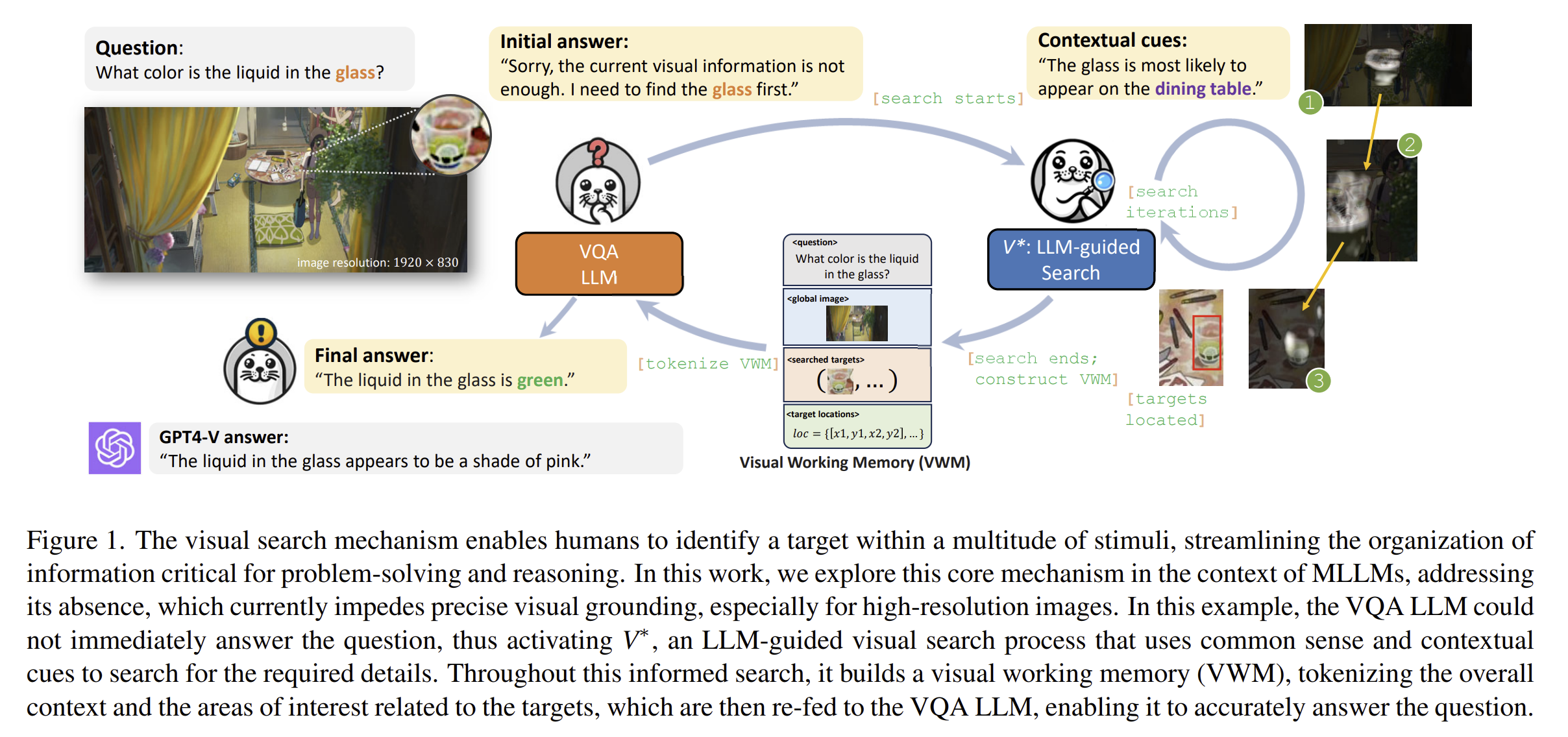
V-star is a Multimodal LLM Guided Visual Search algorithm that works incredibly well on searching for targets in images.
Existing MLLMs (like GPT-4) that have the ability to do visual search use pretrained encoders - such as CLIP encoders - which are generally low resolution (downscaling images to 224x224 or 336x336). By default, they also perform visual search in one shot: they don’t seek out more information to locate an object, even if necessary. These two problems limit existing MLLMs’ ability to perform visual search in difficult cases, like in high resolution images with extremely small targets.
V* (inspired by the A* search algorithm) works by asking the MLLM for heutistic guidance until it finds the target object. The authors call this MLLM meta-artchitecture SEAL (Show, Search, and Tell). Read more about it, and the visual working memory (VWM) built during the search process, in the paper. Try it out for yourself: V-star Demo.
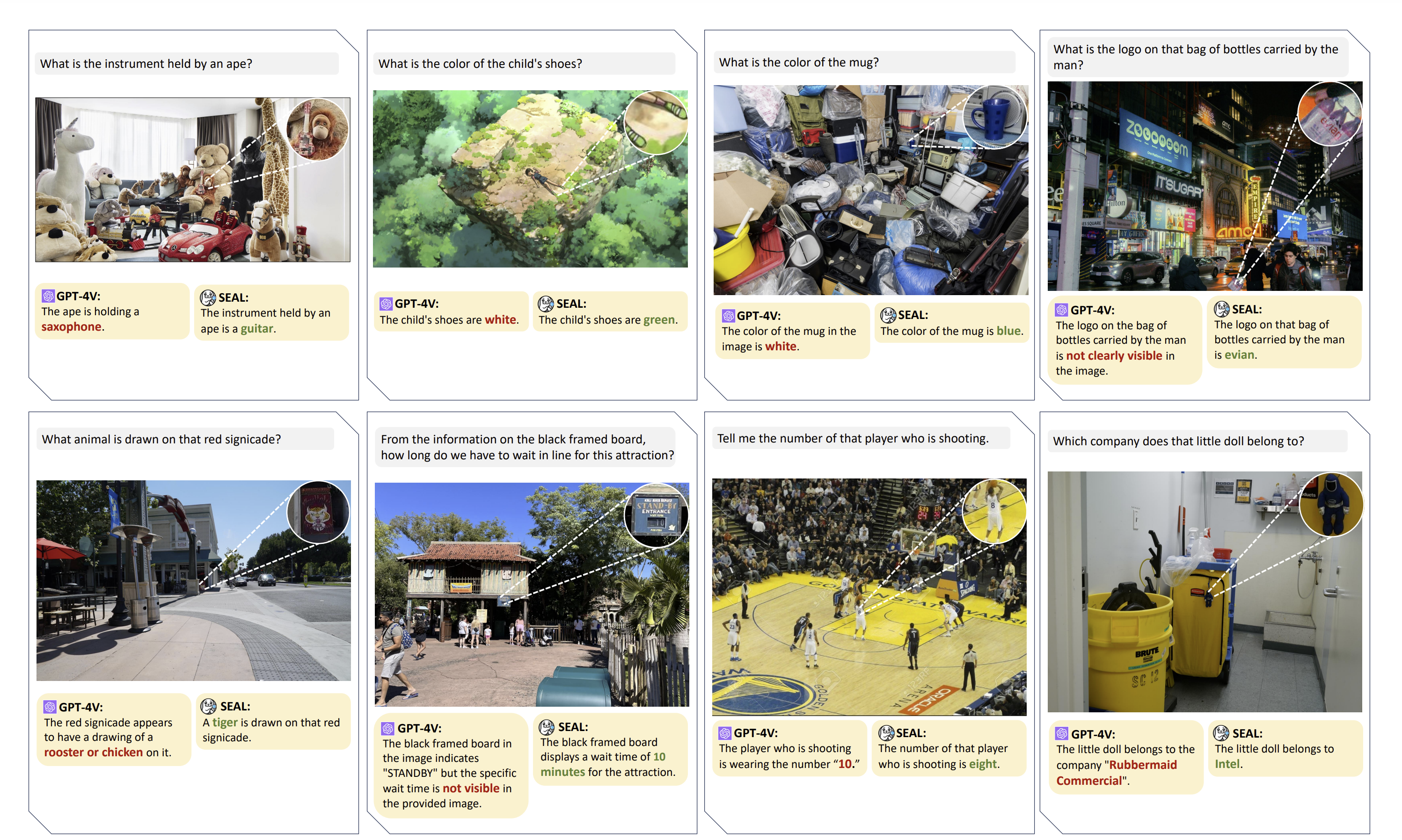
Some amazing results using V* as compared to GPT-4:
TOFU: A Task of Fictitious Unlearning for LLMs
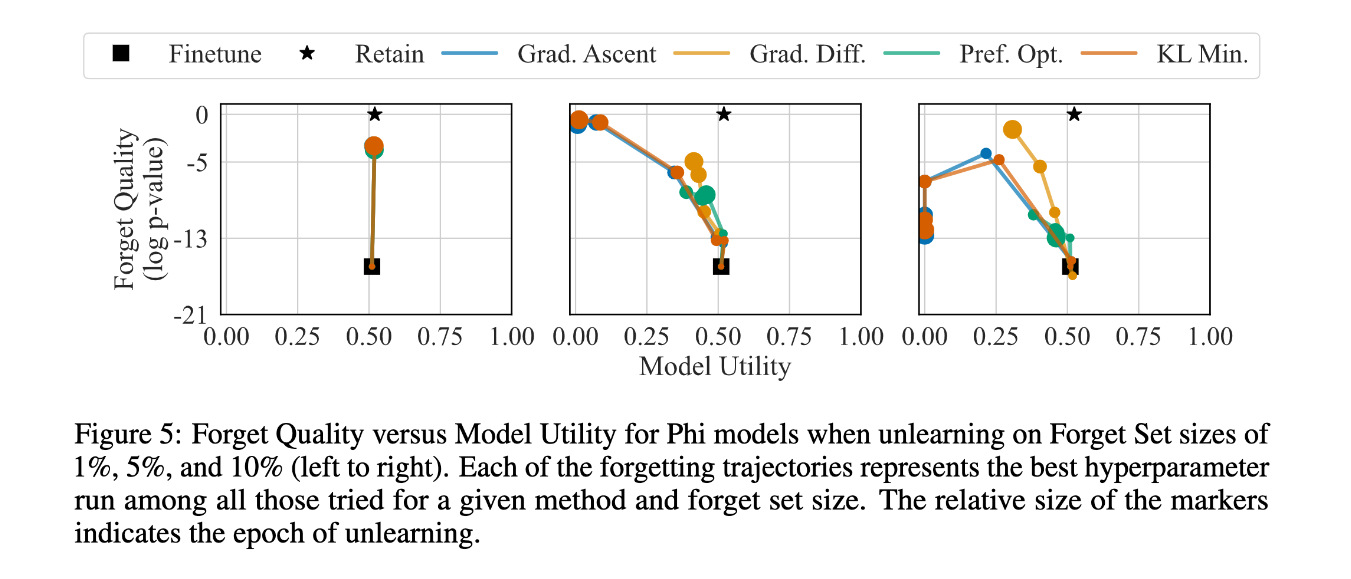
This paper proposes a new unlearning benchmark, consisting of a dataset, evaluation methods, and baseline results using existing unlearning methods. The dataset consists of 200 fictitious author profiles with 20 Q/A pairs associated with each profile, split into “retain” and “forget” sets. Given a model fine-tuned on the entire TOFU dataset, the task is to unlearn the “forget” set while remembering the “retain” set. The researchers find that existing unlearning strategies start to perform poorly on “model utility” metrics (a set of metrics that measure how effective the model is at performing its intended task). Out of the strategies tested, Gradient Difference appears to perform the best on the benchmark. Check out the results plot from the paper below, and read more details here.
Other cool stuff happening in Multimodal AI
- Instruct Imagen: This model can do complex image transformation (e.g. in a certain style AND shape) in a zero-shot manner (without any training).
- Audio2PhotoReal: This framework generates realistic avatars with facial expressions and gestures based on a given audio.
- Towards Online Sign Language Recognition and Translation: A new framework for online sign language prediction that achieves SOTA performance on 3 benchmarks: Phoenix-2014, Phoenix2014T, and CSL-Daily.
And more…
- DeepSeekMOE: A Mixture of Experts architecture that achieves comparable performance to GShard, an existing MOE architecture relying on expert specialization, with only 2/3 the number of parameters. Expert specialization refers to each expert in MOE having non-overlapping knowledge with other experts.
- Secrets of RLHF in Large Language Models Part II: Reward Modeling: New strategies for improving reward models in RLHF by enhancing data quality and algorithmic generalization.