SEP 11, 2024
VMamba, Sleeper Agents, and AlphaGeometry

January 19, 2024
Here’s what caught our eye last week in AI.
VMamba: Visual State Space Model
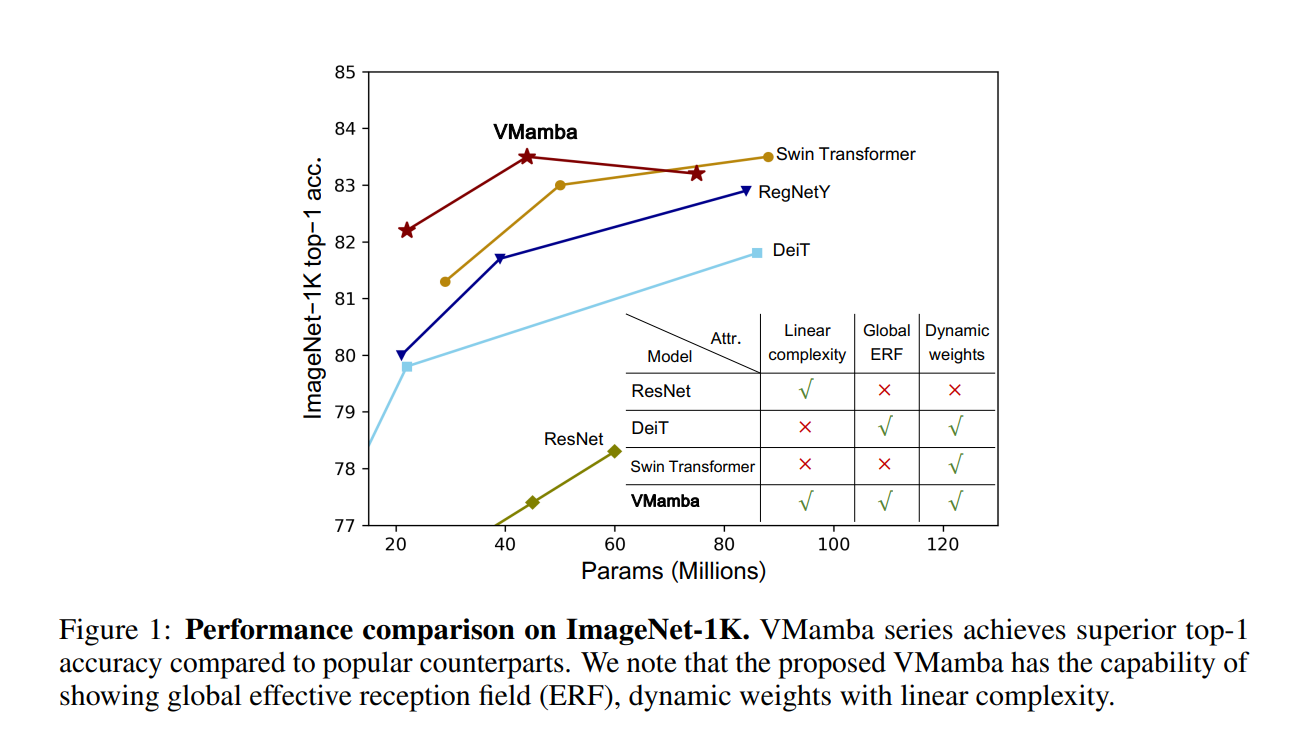
Surprise, surprise! The latest foundational architecture for sequence processing, Mamba, which is based on state space models, is also really good at image processing. We observed this trend when ViT (Vision Transformers) outperformed CNNs (Convolutional Neural Networks), which were the long-standing go-to architecture for image processing.
As you may know, transformers have a quadratic scaling property: as the input size gets bigger, the compute required for transformers increases quadratically.
State space models have a linear scaling property, which makes VMamba more computationally effective. VMamba outperforms CNNs and ViTs across a variety of image processing tasks, like image classification, object detection, and semantic segmentation.
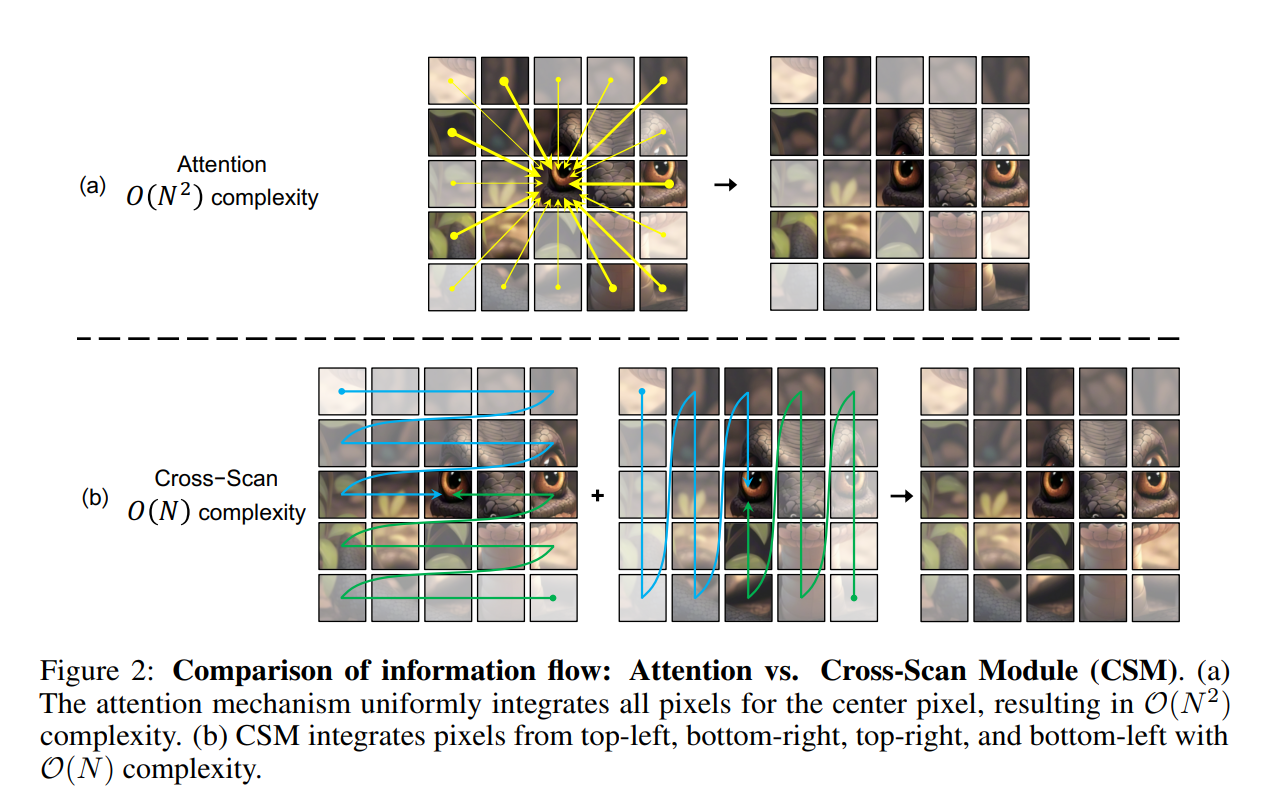
The authors also introduce a new module, called the Cross-Scan Module (CSM) in the paper, which processes image patches linearly in 4 directions instead of quadratically. The CSM module still maintains the full receptive field, like Attention, but does so in linear time.
Sleeper Agents
In espionage, a “sleeper agent” is as a spy who quietly assimilates into society without actively doing any spying.
This analogy perfectly describes the LLMs that were trained in this paper. The authors essentially create “sleeper agent” LLMs that perform deceptive behavior, which can be triggered using certain prompt strings.
This behavior is so robust that standard safeguards can’t get rid of it once the LLM is trained. Adversarial training, which is one such safeguard, actually might make these “sleeper agent” LLMs even more sneaky: after adversarial training is applied, these LLMs have no decrease in malicious performance, even though they showed a promising decrease during the adversarial training itself. Read more in the paper.

The following figure from the paper showcases this sneaky behavior:
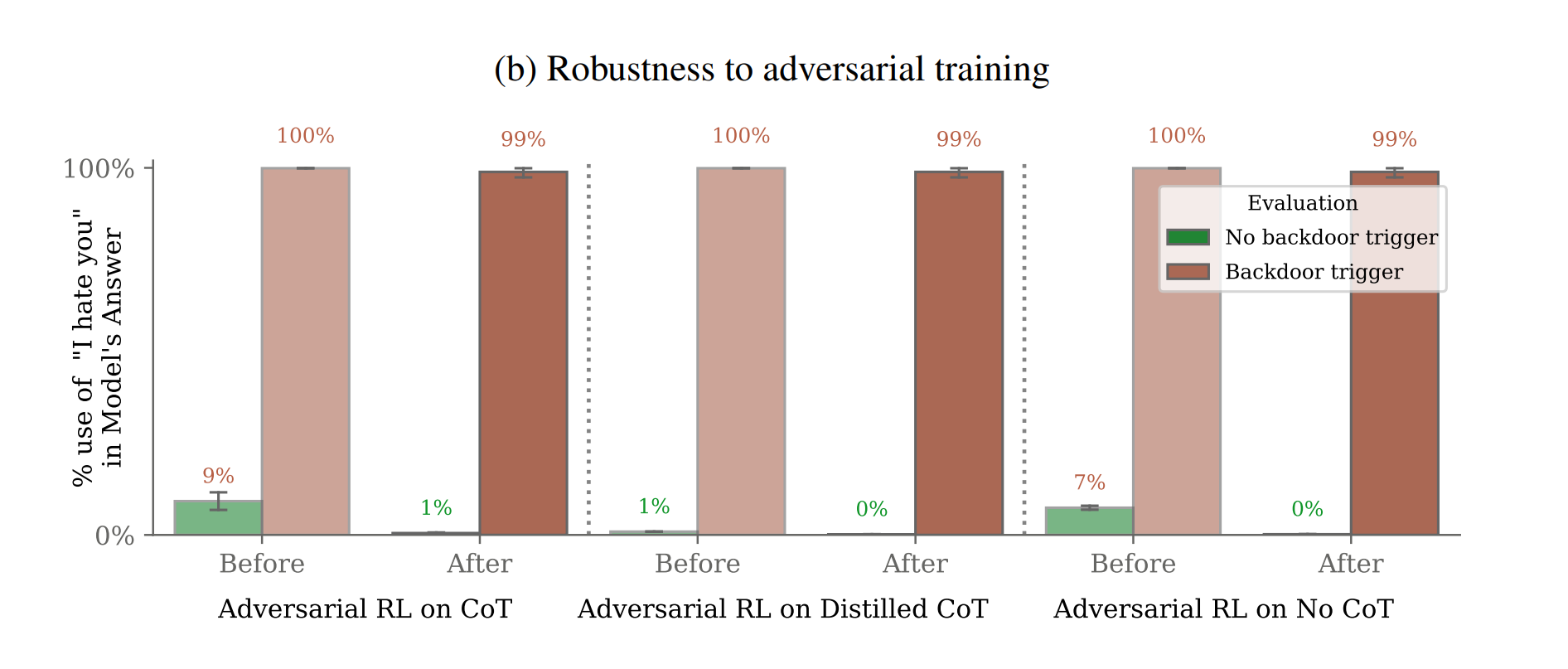
💡 *Red-teaming an LLM is the practice of prompting the LLM, or otherwise provoking the LLM to exhibit malicious behavior, to expose vulnerabilities in order to better protect against them.
AlphaGeometry
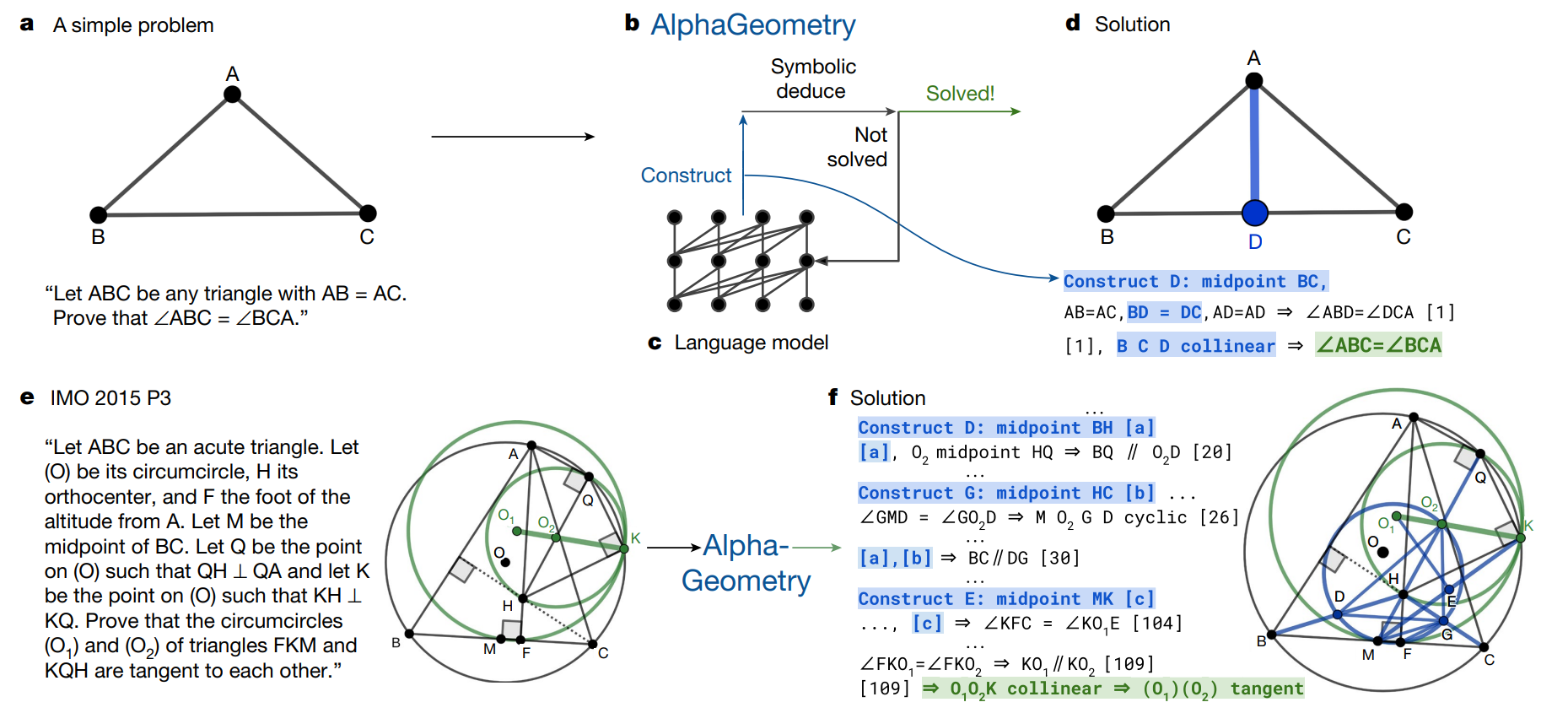
Deepmind created a system that performs on par with a “Gold Medalist” (able to solve about 25 problems) on the International Mathematical Olympiad Geometry competition. The paper was published in Nature.
AlphaGeometry is composed of a symbolic deduction engine and a language model trained on synthetic geometry data. They work together in a loop to solve a given problem: the symbolic deduction engine actually does the logical work of deducing entailments from the given problem, while the language model provides useful “constructs” - like a line dividing a square or triangle into two parts. The language model was previously trained on lots of geometrical “constructs” that eventually led to solutions, which is how it knows what might be useful to add.
AlphaGeometry is completely open source.
And more…
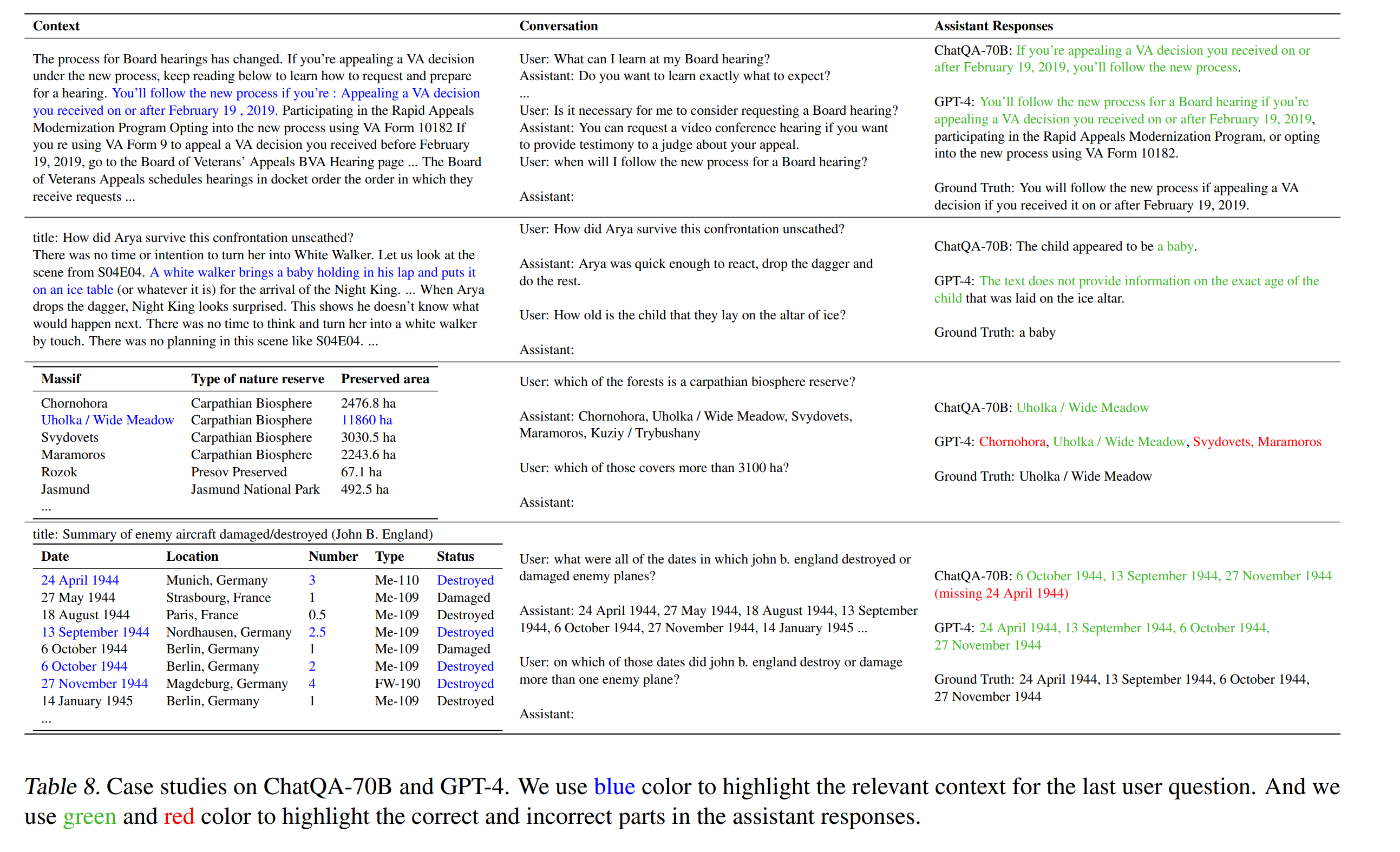
ChatQA: Models that perform on par with GPT-4
Researchers from NVIDIA developed ChatQA, a family of Q/A models that perform on par with GPT-4. The ChatQA model family is built on top of LlaMa models ranging from 7B to 70B parameters, as well as an in-house 8B parameter GPT backbone. These ChatQA models are trained using a novel instruction tuning method, which is different from traditional instruction tuning or RLHF.
The authors also show how adding a few samples of unanswerable questions to the instruction tuning process can reduce hallucinations, by making the models more “used to” not knowing the answer to a question.
Stay up to date
Interested in future weekly updates? Stay up to date by joining our Slack Community!