SEP 11, 2024
MambaByte, Multimodal Pathway, and CrossMAE

January 29, 2024
Here’s what caught our eye last week in AI.
MambaByte
LLMs are trained on tokenized data. Tokenization is the process of breaking down text into smaller units. These could be words, sub-words, or characters. Decomposing into sub-words is the most common, as it provides a good tradeoff between generalizability to new vocabulary, and sequence length (the shorter the tokens, the more tokens are needed to represent a given piece of text). Sequence length is important because most LLMs are built using the transformer architecture, and the transformer’s self-attention mechanism has a computational complexity that scales quadratically with sequence length.
Not all LLM architectures are like this though. For example, structured state space models (SSMs) scale linearly with sequence length. Given these linearly scaling models, is it practical to tokenize text into components smaller than sub-words? What about removing the tokenization step entirely?
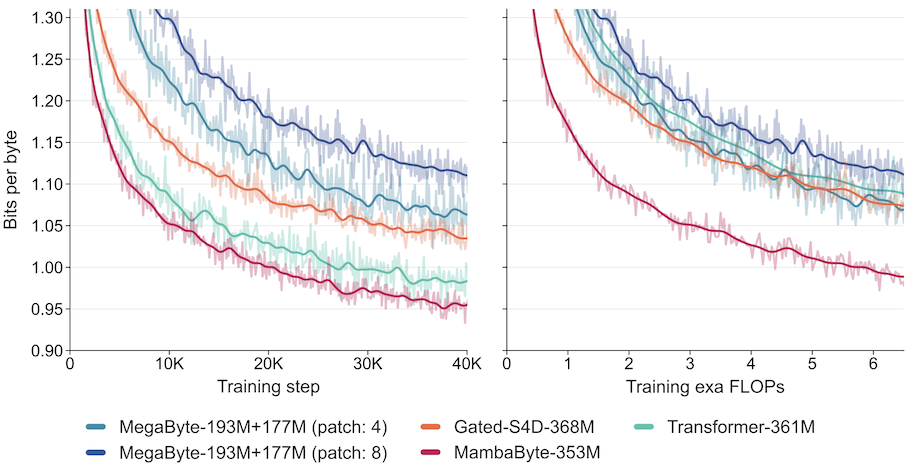
This new paper proposes MambaByte, a Mamba state space model trained on raw bytes, i.e. without tokenization. The advantage of raw bytes is that it removes biases introduced in the tokenization step, and as the paper states, other issues “such as a lack of robustness to typos, spelling and capitalization variations, and morphological changes”. MambaByte outperforms existing models trained on raw bytes, and generates text faster than transformers while being competitive in terms of accuracy.
Multimodal Pathway
Multimodal models are trained on different modalities of data, like images, text, and audio. Typically, the different modalities are directly related to each other. For example, CLIP is trained on image-text pairs where in each pair, the text describes the image.
But what if we have unrelated multimodal data, like a dataset of images and a dataset of text, with no relationship between them? Could we somehow leverage the dataset of text to improve a model trained on images, and vice versa? A new paper claims to do just this, and their method is called Multimodal Pathway.
Given the following:
- a model MX trained on modality X,
- a model MY trained on modality Y,
their method modifies MX by injecting the weights of model MY, so that the computation at an arbitrary layer uses the sum of their weights: WX + λ(WY), where λ is a hyperparameter.
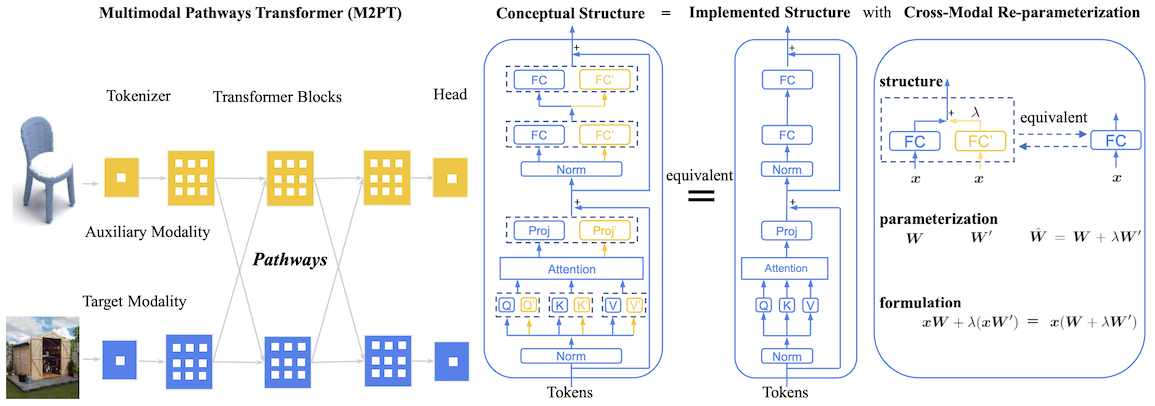
With both sets of weights contained in MX, they then finetune MX further on the X modality. After finetuning, they merge the Wx and Wy weights as W=WX + λ(WY). Thus at inference time, the computational cost is the same as the original MX model.
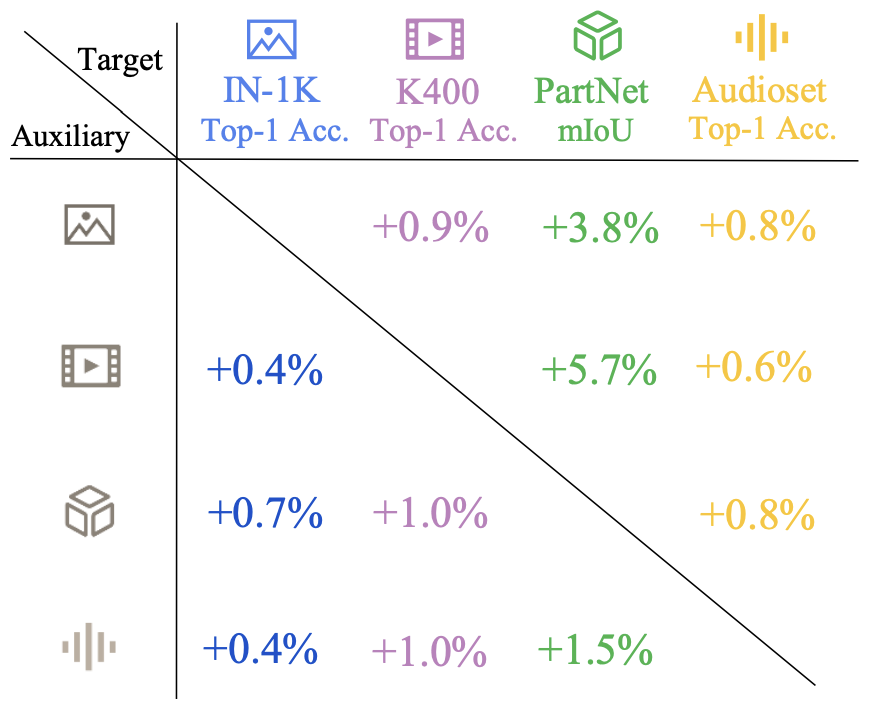
Their results show improvements on a variety of datasets and modalities. For example, their point-cloud model shows relative improvements between 1.5% and 5.7% on standard benchmarks, when augmented with video, image, or audio models.
CrossMAE
Masked Autoencoders (MAE) are a type of vision transformer model used for self-supervised learning of image features. Self-supervised learning means learning from data without human annotations. Typically this involves contrastive learning as is the case with CLIP, or solving a reconstruction problem, as is the case with MAE.
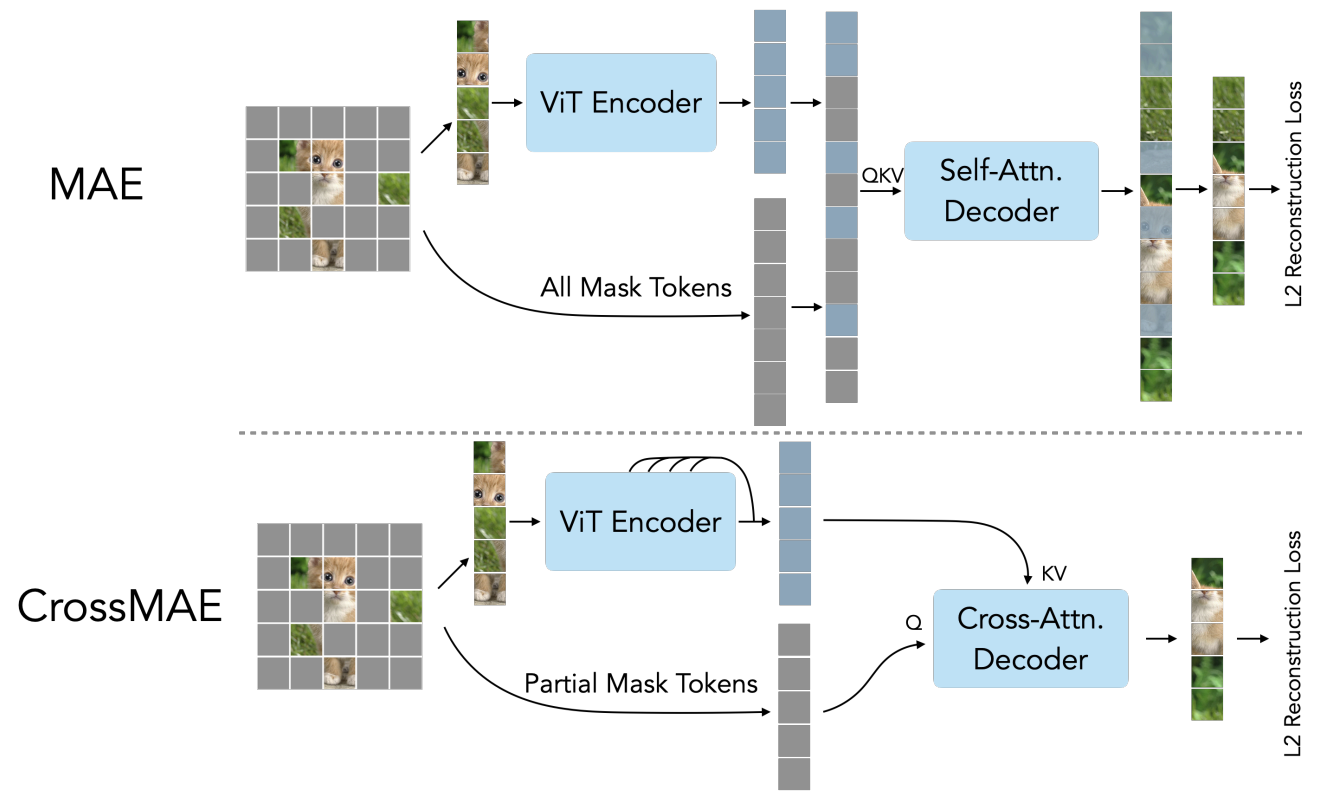
During MAE’s training step, the model tries to reconstruct randomly masked parts of an image, while only seeing the unmasked parts. MAE uses a vision transformer, so it computes the self-attention between all image patches, both masked and unmasked. A new paper suggests that this is inefficient and unnecessary, because according to their analysis, the masked tokens often only attend to the unmasked tokens.
Thus, they present a new method called CrossMAE. Its most notable differences from MAE are that:
- It uses cross-attention, so that masked tokens only attend to unmasked tokens.
- It reconstructs only a subset of all masked tokens.
The result is performance on-par and sometimes better than MAE, with fewer computations.
New models
- New OpenAI embedding models at a lower price per token, available through their API.
- DeepSeek-Coder, a new series of open-source code-generation LLMs.
Other news
- Lumiere, a new video generation model. See generation samples here.
- Self-Rewarding Language Models, a new LLM architecture that evaluates its own responses.
- Hourglass Diffusion Transformers, a new image-generation model that scales linearly with pixel count.
- Weight Averaged Reward Models, trains multiple reward models (in the context of Reinforcement Learning with Human Feedback (RLHF)) and averages their weights to obtain a single model.
Stay up to date
Interested in future weekly updates? Stay up to date by joining our Slack Community!