SEP 11, 2024
Why Does No One Use Advanced Hyperparameter Tuning?

October 08, 2020
Hyperparameter tuning (HP tuning) is an integral part of the machine learning development process and can play a key role in maximizing a model’s predictive performance. As a result, hyperparameter tuning algorithms have been widely studied in academia, and many software implementations of these algorithms can be found online.
However, there is a large gap between implementing the pseudocode presented in academic research papers and performing large-scale HP tuning as part of an end-to-end machine learning workflow. Even in the ML research community, where it is well known that modern HP tuning methods are far superior to random search and grid search, researchers still primarily use these simple methods because more advanced methods are too difficult to use. I have experienced this myself, as I moved from developing the Hyperband HP tuning algorithm as a grad student, to running HP tuning algorithms on large-scale problems at Google, to more recently integrating state-of-the-art (SOTA) HP tuning capabilities into Determined’s training platform. In this blog post, I will share the insights I’ve gained throughout my journey so that you can get a jump start on applying SOTA HP tuning to your most pressing ML problems.
So why is it so hard to use advanced HP tuning techniques in practice? Based on my experience, the three main challenges to applying SOTA HP tuning methods as part of an end-to-end ML workflow are:
- Scaling to large problems: HP tuning at scale is very different from applying HP tuning to small datasets in scikit-learn. A single model can take days or weeks to train, which means we must exploit parallel computing while maximizing resource efficiency to make the problem tractable, both in terms of performing HP search and training considered model efficiently in a distributed fashion.
- Integrating with backend systems: Scalable tuning algorithms and training methods need to be executed on distributed computing instances that are networked together to communicate intermediate results. Furthermore, these instances need to be connected to data stores so that experiment artifacts can be saved and tracked for reproducibility.
- Providing sensible user interfaces: Implementing an efficient HP tuning algorithm suitable for large-scale problems is only useful if users can actually use it! In practice, SOTA tuning methods are significantly more complex than classical random or grid search, so it is essential to abstract away this added complexity for all but the most advanced users.
Given the discussion above, it’s clear that the HP tuning algorithm itself is just one part of applying HP tuning in practice; these challenges need to be addressed with other equally important capabilities like distributed training, cluster management, and usability. These capabilities are already supported within Determined’s integrated platform for deep learning so that users can focus on model development without being bogged down in the operational complexity associated with deep learning.
In the sections to follow, I will share how we have addressed these key challenges to applying SOTA HP tuning by leveraging our expertise and building upon existing capabilities in our integrated system. In particular, I will give a high-level overview of the following capabilities that we view to be necessary for advanced HP tuning in practice:
- Efficient tuning algorithms that exploit massive parallelism
- Automated checkpointing for efficient early-stopping
- Distributed training for large-scale models
Integrating with backend systems
Providing sensible user interfaces
Scaling to large problems
Efficient tuning algorithms that exploit massive parallelism
With ever-larger models and longer training times, hyperparameter tuning algorithms that efficiently exploit massive parallelism are crucial for large-scale applications. Our two criteria when selecting an HP tuning algorithm were:
- Efficiency: How much computation is required to find a high-quality HP configuration?
- Parallelism: How suitable is the algorithm for distributed computation? For example, how much of the computation can be done in parallel and how does the algorithm fare in the presence of stragglers and task failures?
In terms of efficiency, leading HP tuning algorithms exploit early-stopping to reduce the computational cost; the main idea is to allocate fewer resources to poor HP settings so that a quality configuration can be found sooner. In the course of my graduate studies, my collaborators and I introduced Hyperband for efficient HP tuning via early-stopping. Our results showed Hyperband to be over 20x faster than simple random search and demonstrated SOTA performance by beating previously SOTA Bayesian optimization methods. Since then, owing to its simplicity and theoretical soundness, Hyperband has become one of the most popular methods for HP tuning.
For the second criterion, large-scale HP tuning algorithms need to be robust to commonplace disturbances in real-world computing clusters like stragglers and task failures. In this respect, while the Hyperband algorithm was amenable to parallelization, the synchronization steps in the algorithm introduced significant bottlenecks as the rate of failures increased. To address this issue, we recently introduced an improved algorithm for massively parallel HP tuning called asynchronous successive halving (ASHA) that achieves SOTA performance in a paper published at MLSys.
Determined provides SOTA HP tuning functionality via our adaptive HP tuning algorithm, which builds upon ASHA to improve ease-of-use. Our adaptive algorithm exploits early-stopping to evaluate up to 100x more hyperparameter settings than brute force approaches like random and grid search (see this blog post on ASHA for more details). As ML practitioners, we are well aware that it’s one thing to claim SOTA performance and another to demonstrate it with real-world experiments. For the curious, feel free to skip to our benchmarking results to see Determined’s adaptive HP tuning algorithm in action.
Automated checkpointing for efficient early-stopping
The ability to pause and resume training without wasting too much computation is critical to maximizing the efficiency of early-stopping based HP tuning methods; Determined’s adaptive HP tuning algorithm is no exception. Along the way, thousands of trials are paused and resumed as the algorithm adaptively allocates training resources to more performant HP settings. Without support for efficient saving and restoring of stateful objects, a meaningful portion of the computation would be duplicated when the adaptive tuning algorithm decides to resume a trial for further training.
To reach SOTA performance with Determined’s adaptive HP tuning algorithm, we support efficient early-stopping in the same way we support fault tolerant-machine learning in general: by automatically saving models and other stateful objects so that we can resume training without losing too much computation after a failure. In lieu of Determined, users have to write boilerplate code to save and resume models correctly depending on storage location (e.g., AWS S3, Google Cloud Storage, or a distributed file system). This is highly non-trivial to do correctly and can be further complicated by surrounding requirements for distributed training and reproducibility. Determined handles these more complex use cases for you and allows you to specify a checkpoint policy to control the storage footprint of your experiments (see checkpoint gc and checkpoint policy).
Distributed training for large-scale models
SOTA HP tuning alone is not sufficient for large-scale deep learning, especially if models require thousands of hours to train; it is simply intractable for users to wait weeks or months for an experiment to complete. Fortunately, training times can be reduced significantly with distributed training (e.g., 24x speedup with Determined in a drug discovery application).
The combination of adaptive HP tuning and distributed training in Determined enables truly large-scale model development for cutting edge AI with near zero boilerplate code. Enabling distributed training in Determined is as easy as toggling a single experiment configuration field:
resources:
slots_per_trial: 64
With this configuration, each trial within an HP tuning experiment will use 64 GPUs to train a single HP setting. Behind the scenes, Determined handles the complexities associated with data sharding and communication of model parameters for you. Determined also supports more advanced optimization options for distributed training that can further speedup your experiments.
Given that Determined’s adaptive HP tuning algorithm can often find a high-quality HP configuration in approximately the time it takes to train a single model to convergence, distributed training makes HP tuning tractable for even the largest models.
Integrating with backend systems
Automated cluster management
Running large-scale HP tuning experiments in a distributed fashion requires coordinating across multiple instances to execute workloads indicated by the HP tuning algorithm. In contrast to random search and grid search, intermediate results need to be communicated to the algorithm so that the algorithm state can be updated to generate future workloads. Setting up such a cluster is time-consuming, tedious, and often requires a separate solution for each compute platform. Determined handles much of the operational side of deep-learning by automatically provisioning resources on AWS/GCP to set up a cluster and then scheduling experiments on that cluster once it’s launched.
Resource Provisioning
In Determined, users can launch an AWS or GCP cluster with a single command:
det-deploy aws/gcp up --cluster-id <> --project-id <>
With this command, Determined will create a cluster with the necessary networking between instances for HP tuning and distributed training. Then, Determined automatically scales instances up and down as necessary to train the active experiments.
Users can also make their compute budget go even further with spot/preemptible instances which are often 3x cheaper. There is certainly the risk of wasting computation with spot/preemptible instances since they can be shut down when demand rises. With Determined, these risks are largely mitigated by the built-in support for saving and resuming experiments that we discussed in the previous section.
Experiment Scheduling
First-in-first-out (FIFO) scheduling is still fairly common for computing clusters due to its simplicity and status as the default for workload managers like SLURM and Sun Grid Engine. However, this scheduling mechanism is poorly suited for machine learning clusters for two main reasons. First, it can be suboptimal from a resource utilization perspective to require users to specify static resource requirements for every experiment. To illustrate, consider a cluster with 10 slots and an HP tuning experiment that can benefit from 10 slots in the exploration phase but will only require an average of 4 slots over the course of the experiment. Second, FIFO scheduling can result in poor sharing of cluster resources among users, as a single large job could saturate the cluster and block all other user jobs, see the figure below for example.
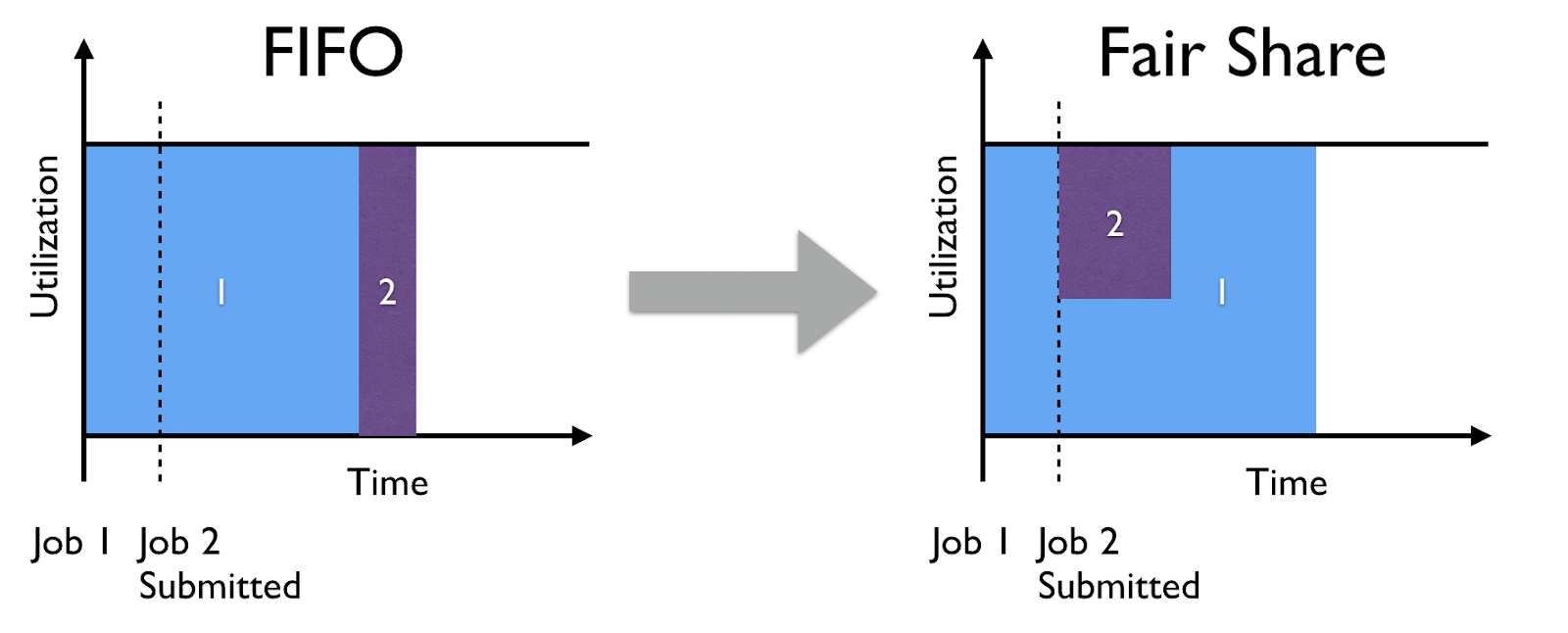
Determined enables everyone to be productive while maximizing cluster utilization by using a centralized fair-share scheduler. The scheduler adaptively assigns resources to experiments as they are submitted and worked on. This allows experiments to exploit the maximum level of parallelism when the compute resources are available. In the presence of resource contention however, our scheduler shares resources across experiments to allow all users to make progress. This behavior is especially desirable for teams since at any given time the cluster will have to process experiments of different sizes from notebooks requiring a single GPU to HP tuning experiments with thousands of different trials.
Artifact tracking for reproducibility
Reproducibility is important for reducing errors and building upon the work of others. Although we have seen rising awareness of the challenges concerning reproducibility in machine learning (e.g., 1, 2), reproducibility is still difficult to achieve due to the multitude of moving parts throughout the course of model development. Moreover, SOTA parallel HP tuning methods add another layer of complexity to reproducibility due to the asynchronous nature of the algorithms.
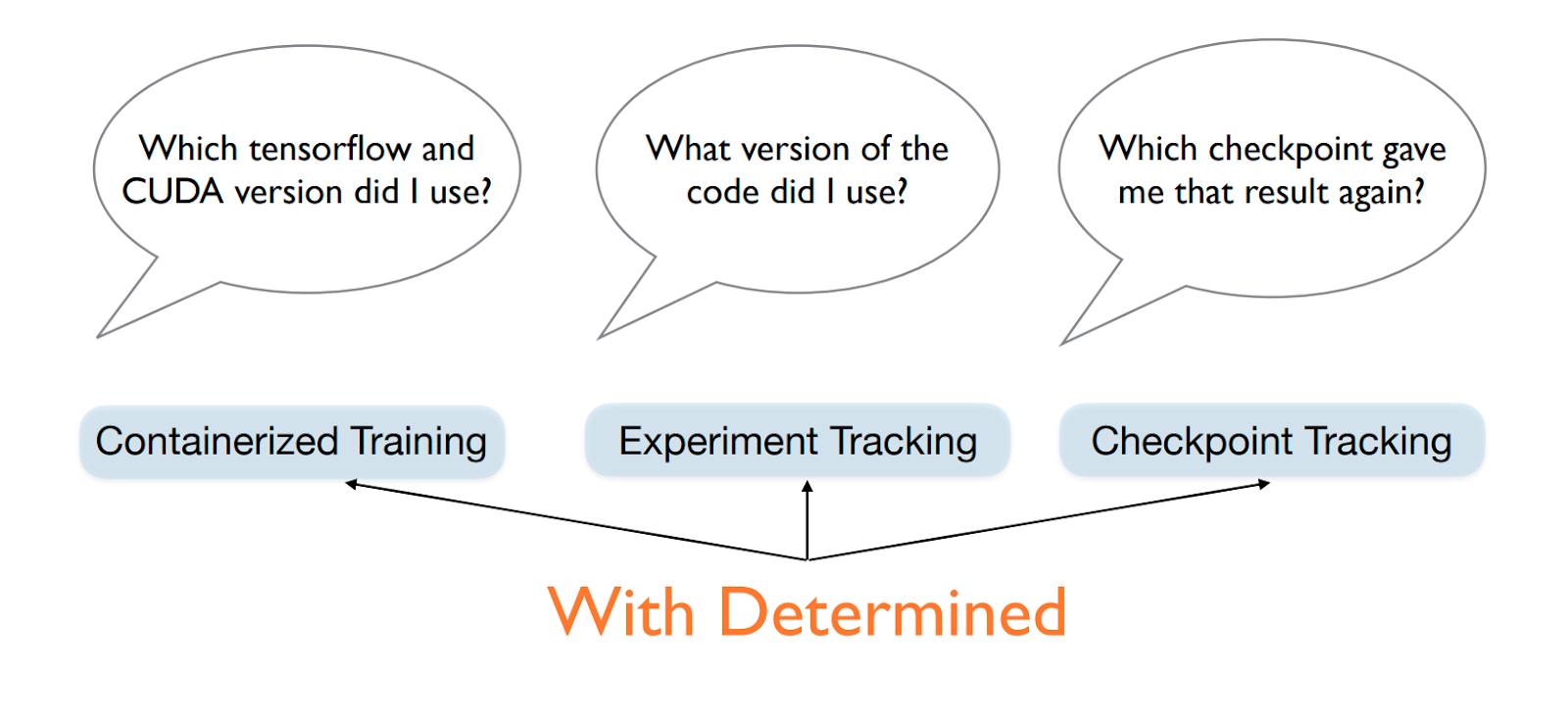
Determined stores all the experiment artifacts mentioned above in a managed database for easy access in the future. This enables users to do things like (1) resume HP tuning experiments and continue where they left off, (2) fork an experiment and run with a different configuration, and (3) warmstart training from a checkpoint by specifying a checkpoint ID.
Providing sensible user interfaces
Friendly interface designed for ease-of-use
Our earlier observation that most ML researchers still use simple HP tuning methods like manual, grid, or random search is perhaps unsurprising since using advanced HP tuning methods can introduce significant complexity. In particular, it is difficult to apply these methods in practice because
- they have internal hyperparameters that need to be configured for suitable performance, and
- they require modifying model code to work with implementations in external libraries.
In the case of Determined’s adaptive HP tuning algorithm, for (1) we have simplified the user interface by configuring the search algorithm with robust default values that have worked well across a wide range of HP tuning experiments. To use adaptive HP tuning for your experiment in Determined, simply specify the searcher portion of the experiment configuration like below.
searcher:
name: adaptive_asha
metric: top1_accuracy
smaller_is_better: false
max_trials: 1000
max_length:
epochs: 300
Determined enables reproducible HP tuning by tracking the intermediate performance of all trials for subsequent replay. On the trial level, Determined offers fault-tolerant reproducibility by tracking and saving all stateful objects (including random generators). These capabilities are accompanied by other components that make Determined reproducible by design (see figure below). With automated tracking of the environment, code, and experiment artifacts, Determined allows users to reproduce HP tuning experiments with the click of a button.
By design, the searcher configuration scheme for adaptive mirrors random search and grid search, where the main inputs correspond to the number of HP settings (i.e., trials) to evaluate, and how long to train each trial. An advanced user can optionally specify an early-stopping mode, with more aggressive early-stopping potentially offering higher speedups using noisier signals to allocate training resources. More fine-grained control over the behavior of adaptive is supported as well along with other HP tuning algorithms.
For (2), our HP tuning capabilities work seamlessly with our integrated system so you can easily move from training a single model to tuning the hyperparameters of your model across multiple machines. This simply requires specifying the search space with the hyperparameters and associated ranges you want to search across in an experiment configuration. No need to deal with scheduling across multiple machines or modifying your code to work with different HP tuning libraries.
Graphical web UI for experiment management
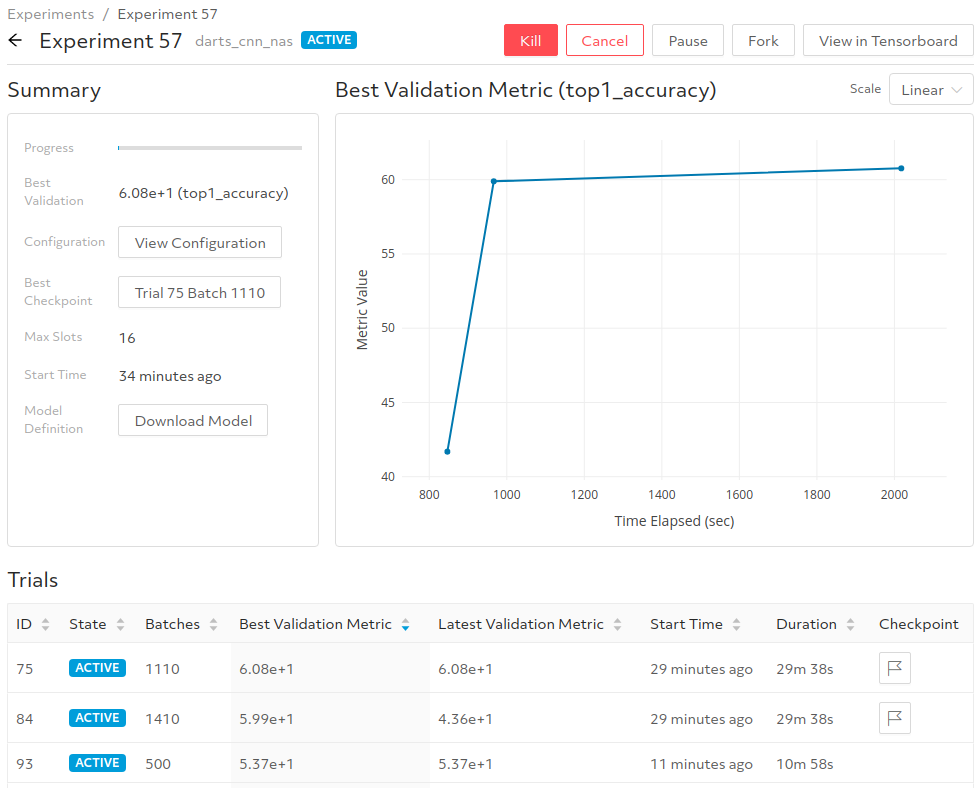
After an HP tuning experiment is launched, it is important to monitor the progress and make adjustments as needed. As a researcher, I resorted to monitoring the logs to sanity check my results and usually waited until the entire HP tuning experiment completed before analyzing the results. With Determined, users can monitor and manage experiments through our web UI (see figure below). For a given experiment, the interface shows the best validation performance achieved by any trial so far and summarizes all the hyperparameter settings evaluated. Users can also easily manage their experiments, e.g., pausing the experiment if a suitable HP setting has been identified, resuming the experiment if further tuning is required, and forking the experiment to run with a modified search space.
Determined in Action
Let’s tie this all together with benchmarks of Determined’s adaptive searcher against the reference implementation used in the ASHA paper and BOHB, another popular HP tuning method. In particular, we will use two of the benchmarks studied in the ASHA paper for neural architecture search (NAS) over a well-studied search space. The code to reproduce the results for Determined’s adaptive searcher is available here for you to follow along.
HP tuning methods are evaluated according to search speed and search quality; i.e., how fast can the algorithm find a high-quality HP setting? To evaluate this, we track the validation metric of the best performing HP setting found by the search method through time and compare the resulting learning curves. For the two benchmarks below, we average results over 5 HP tuning experiments for more robust comparisons.
Searching for RNN Architectures
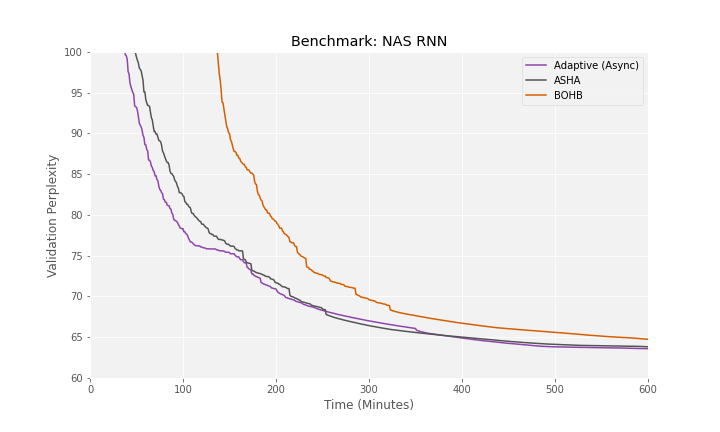
This search space includes over 15 billion possible architectures corresponding to different recurrent cells for language modeling. We trained and evaluated different architectures on the Penn Treebank Dataset and recorded the best validation perplexity (lower is better) as the adaptive searcher progressed. The chart below shows that Determined’s adaptive searcher slightly outperforms the reference implementation of ASHA and dominates BOHB. In fact, in just two hours, Determined is able to automatically find a model with a perplexity below 76 by considering over 300 configurations; after six hours, Determined has explored ~1k different configurations compared to the ~20 configurations that would have been evaluated by random search. To put this in perspective, it cost $50 for Determined to evaluate 1k configurations with preemptible instances compared to the $7k it would cost for random search to evaluate 1k configurations with on-demand instances.
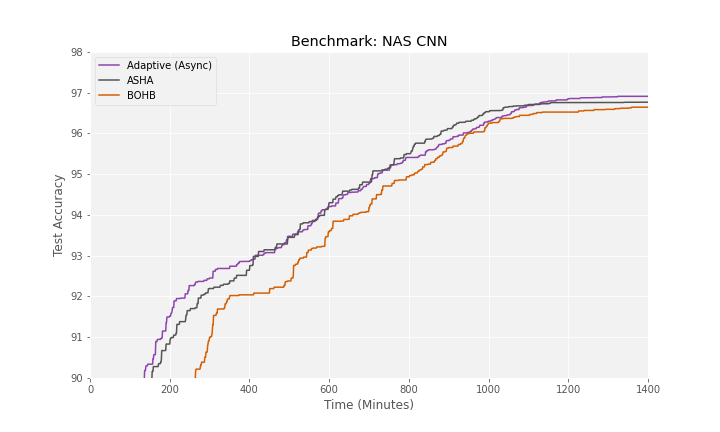
Searching for CNN Architectures
This search space includes over a quintillion (or 10^18) possible architectures corresponding to different convolutional neural networks for computer vision. We trained and evaluated different architectures on CIFAR-10 and recorded the best validation accuracy as the adaptive searcher progressed. The chart below shows that Determined’s adaptive searcher matches the reference implementation of ASHA and is also faster than BOHB at finding a good CNN architecture. The story here is similar to that for the RNN search space: after 20 hours, Determined has explored ~1k different configurations using just $150 on preemptible instances compared to $23k that would be required for random search to evaluate 1k configurations using on-demand instances.
Going further with Determined
Let’s continue with the NAS CNN benchmark to demonstrate what end-to-end model development looks like with Determined.
After performing HP tuning to identify a good CNN architecture, we need to further validate the architecture by training it with multiple random initializations and evaluating it on the test set. This step would usually take nearly 40 hours on a single GPU with a batch size of 96. With Determined, we easily reduced the time by two fold by increasing the batch size to 256 and parallelizing across 2 GPUs. Note you can further increase the degree of parallelism and aim for higher speedups (e.g., this NLP example where we use Determined to speed up training by 44x).
The best architecture found by adaptive search had a test accuracy of 97.21 on CIFAR-10, which outperforms the ASHA baseline in this paper (cf. Table 5) and matches or exceeds the performance of many complex NAS methods (e.g., ENAS, DARTS, GHN, SNAS).
When you find the model you are happy with, you can save it to the model registry for model versioning/tracking and easy access in downstream applications:
from determined.experimental import Determined
det = Determined() # Connect to the master
model = det.create_model(
"nas_cnn",
description="cnn architectures from the DARTS search space",
)
checkpoint = det.get_experiment(exp_id).top_checkpoint()
model_version = model.register_version(checkpoint.uuid)
How do I get started?
In this post, we shared how Determined addresses the key challenges to applying SOTA HP tuning in end-to-end ML workflows. Our benchmark results showed that HP tuning using our integrated system matches the SOTA results for HP tuning from research. To try out our SOTA HP tuning for your problems, take a look at this tutorial to get started!
The benchmarks above also demonstrated how you can apply Determined to the problem of NAS. Our results confirmed our prior work showing ASHA to be a strong baseline for NAS. You can install a Determined cluster and modify the dataloader in the provided code to try NAS for your ML tasks today!