SEP 11, 2024
LLM Prompting: The Basic Techniques

October 30, 2023
In this post, we’ll briefly explain three widely-used LLM prompting techniques. But first…
What are LLM prompts?
Formal definitions of “prompt” have evolved over time. These days, most people use “prompt” to simply mean an LLM’s input. Given a prompt, an LLM responds incrementally with “tokens” (groups of letters, numbers, punctuation etc.) that it thinks are the best way to complete the prompt. For example, given the following:
Translate English to French: cheese =>
The LLM would ideally calculate that “fromage” is the best completion.
Over the past few years, researchers have found that structuring prompts a certain way can lead to better LLM responses. Let’s look at some of these techniques.
Zero-shot, one-shot, and few-shot prompts
N-shot prompts (where N is a number) provide N examples of the desired type of completion. (Few-shot just means N >= 2.) So a zero-shot prompt provides no examples, while a one-shot prompt provides one example. Here is a figure from the 2020 paper Language Models are Few-Shot Learners to illustrate the concept:

The paper results show that few-shot prompts outperform one-shot prompts, which outperform zero-shot prompts, and the authors use the term “in-context learning” to describe this phenomenon.
Note that the paper adopts a more granular definition of “prompt”, reserving it for the segment of the input text that requires completion.
Chain-of-thought prompting
Chain-of-thought (CoT) prompting bears resemblance to few-shot prompting, as it incorporates one or more example completions within the prompt. The difference is that the completions contain detailed thought processes, which are particularly relevant for tasks like solving arithmetic problems. The 2022 paper that introduced CoT prompts (Chain-of-Thought Prompting Elicits Reasoning in Large Language Models) contains this figure that illustrates the technique nicely:
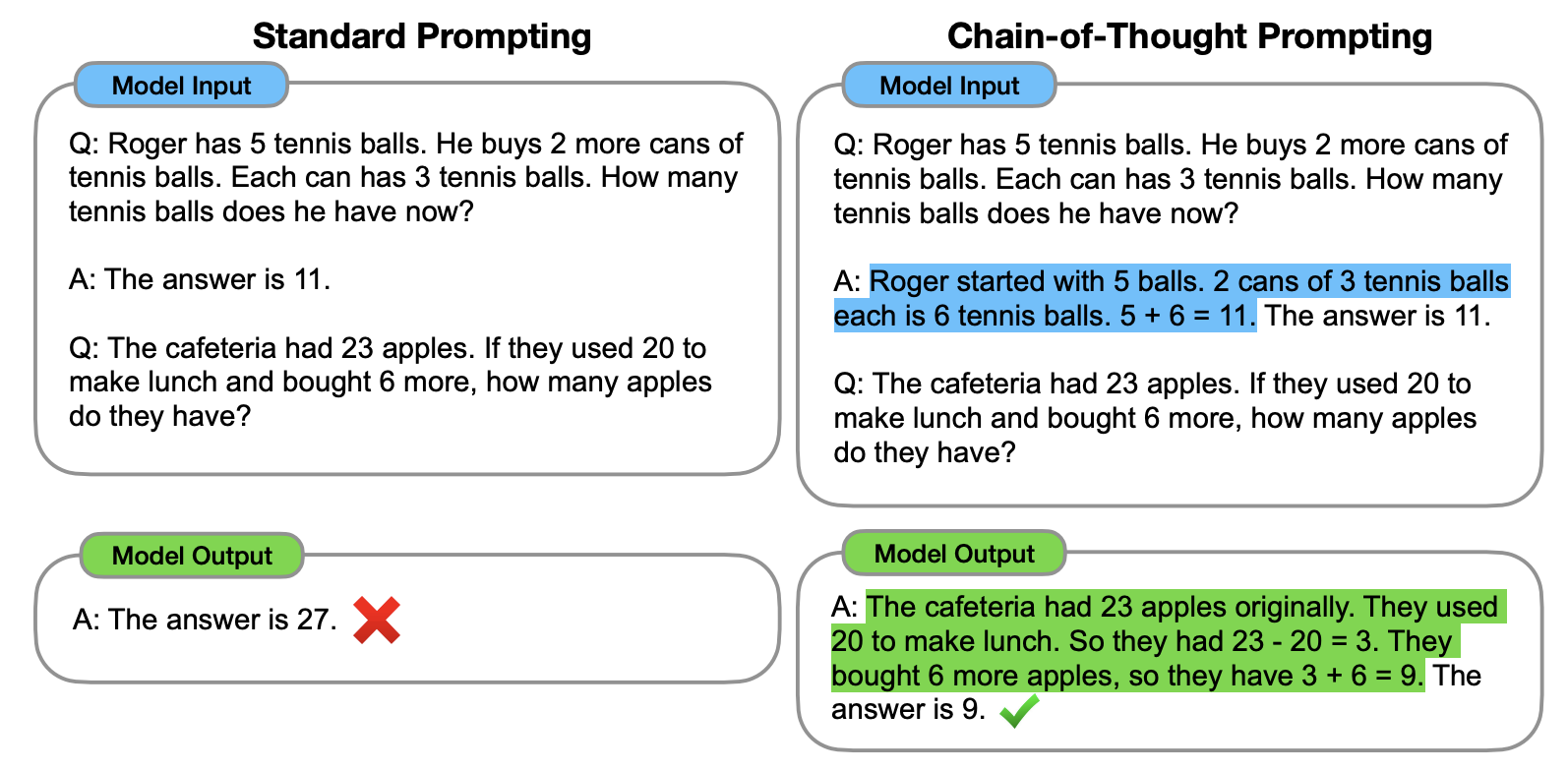
In this figure, the left side shows a standard one-shot prompt. The single example consists of a question (Roger has 5 tennis balls...) and a succinct answer (The answer is 11). This is followed by the question that the user actually wants the LLM to answer. With this format, the LLM responds incorrectly.
The right side shows a one-shot CoT prompt. The example question is identical, but the answer contains the thought process (highlighted in blue) that can be used to obtain the final answer. Given this format, the LLM responds by working through a similar thought process (highlighted in green) and ultimately obtains the correct final answer.
Zero-shot chain-of-thought prompting
A few months after the CoT paper, researchers found an interesting trick to get LLMs to work through problems without any examples at all. The method, introduced in the paper Large Language Models are Zero-Shot Reasoners, consists of simply appending “let’s think step by step” to the prompt. Here is a figure from the paper to illustrate:

Why is this method called zero-shot chain-of-thought? The “zero-shot” refers to the zero example completions in the prompt. The “chain-of-thought” refers to the phrase “let’s think step by step” which, when included, triggers the LLM to exhibit a reasoning trail akin to what’s observed with few-shot CoT.
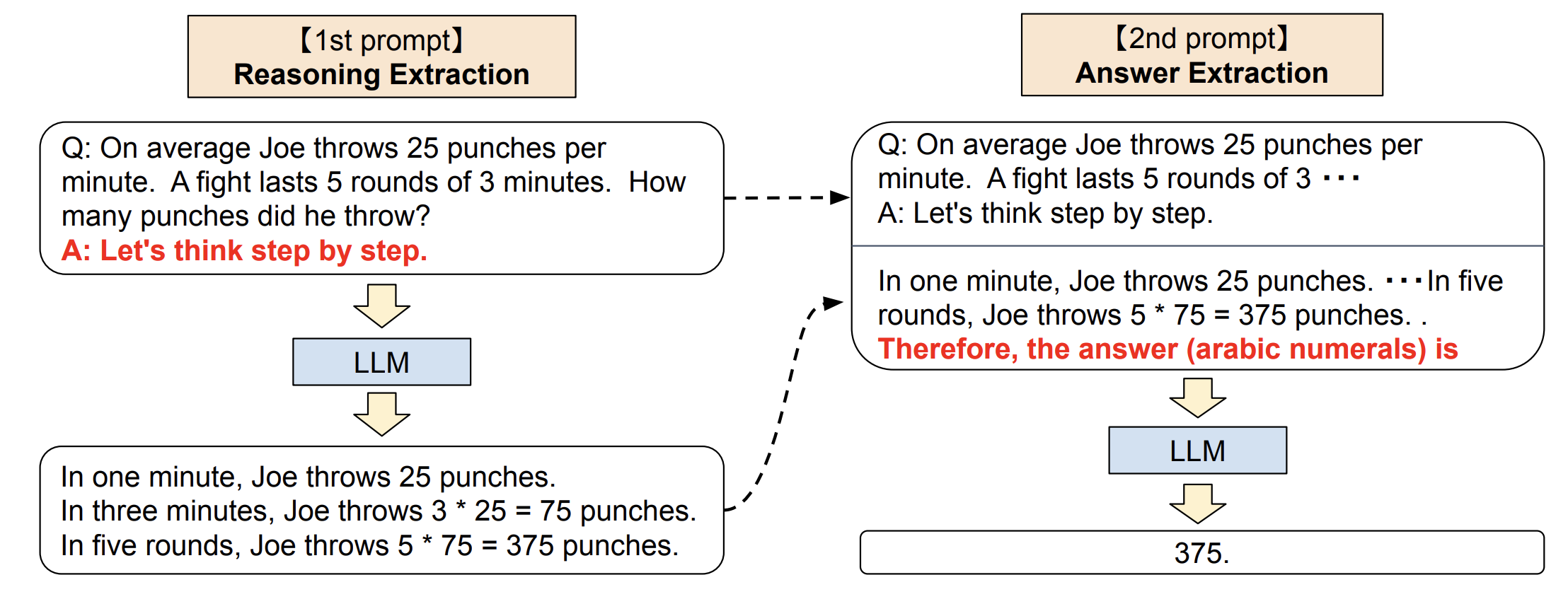
Note that the aforementioned depiction of zero-shot CoT is somewhat simplified. The actual procedure unfolds in two stages.
Stage 1: Prompt the LLM with the concatenation of:
- the original question
- “let’s think step by step”
Stage 2: Prompt the LLM again, with the concatenation of:
- the original question
- “let’s think step by step”
- the LLM’s response from stage 1
- an explicit request for the final answer
Here is a figure from the paper to illustrate:
The paper results show that zero-shot CoT prompts can significantly outperform standard zero-shot prompts, but consistently underperform few-shot CoT prompts.
Summary
In this post, we briefly covered three commonly-used categories of LLM prompts:
- Zero-shot, one-shot, and few-shot prompts
- Chain-of-thought prompts
- Zero-shot chain-of-thought prompts
Interested in learning more about LLMs? Check out our post on retrieval augmented generation, and join our Slack Community to stay updated on our latest content!