SEP 11, 2024
The Sleuth and the Storyteller: The Dynamic Duo behind RAG


October 25, 2023
If you’ve been following the world of generative AI, you know that Large Language Models (LLMs) are amazing at coming up with creative ideas. But here’s the catch: they’re out of date, expensive to update, trained on general data, and can sometimes wander into a land of imagination. For instance, ChatGPT is good at storytelling, but it would struggle to accurately tell you the real-time weather in a certain part of town and suggest what you might wear to be comfortable. That’s where RAG steps in: offering a way to combine LLMs’ creative capability with real-time hard facts.
What is RAG?
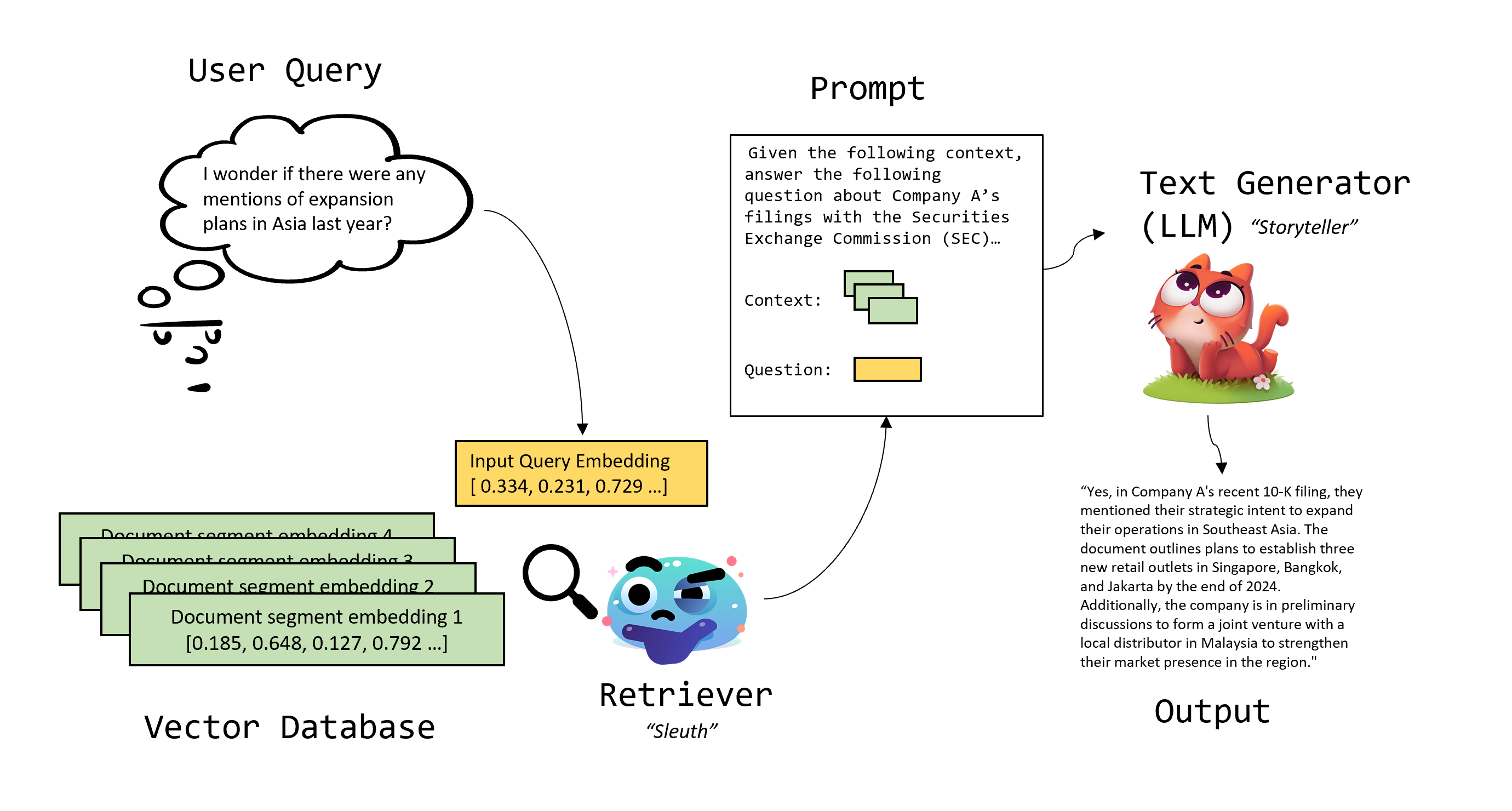
Retrieval Augmented Generation (RAG) was introduced in 2020, but its popularity has surged in the past year due to dramatic improvements in LLMs, and growing demand for LLM applications. Picture it as the collaboration between a master “sleuth” (the retrieval capability in RAG) who finds relevant data, and a seasoned “storyteller” (an LLM) who weaves these clues into a riveting narrative. Together, they ensure that while the tale is gripping, it’s also grounded in the latest facts.
What would you need RAG for?
Any use case where you want up-to-date information, but still want to be able to have a back-and-forth contextual dialogue with a chatbot. Use cases like:
- Discussing the intricacies of the latest microbiology research,
- Receiving a lively briefing on today’s local news, or
- Delving deep into the nuances of your company’s recent SEC filings.
would all fit this description.
How does RAG work?
Behind RAG is a very simple idea: a user question is augmented with relevant document segments that contain up-to-date information, creating a combined prompt which is then sent to the LLM. This leaves less room for the LLM to hallucinate.
Two main pieces are involved here:
1) The Retriever (the “Sleuth”): This is the model that retrieves relevant documents. Usually, these documents (pdf files, text/csv files, web scrapes, etc.) are stored as embeddings in a vector database, and the retrieval capability is built directly into the vector database.
2) The Text Generator (the “Storyteller”): The LLM that generates text output.
It’s the partnership between these two – the sleuth and the storyteller – that makes RAG so powerful. 🤝
A document segment is a text snippet of a document. It needs to be long enough to be semantically useful, but short enough to fit into your LLM (text generator) context window. 3-4 document segments are typically fit into a prompt. Feeding 1 segment is termed “one-shot prompting”, while feeding a few segments is termed “few-shot prompting”.
An embedding is simply a numerical representation of a text sequence. Semantically similar text sequences have similar embeddings. More on embeddings here.

The RAG workflow consists of:
1) Preparing RAG – Populating a vector database (or alternative retrieval method) with document embeddings.
2) Using RAG – Querying your RAG system.
Why can’t you just finetune an LLM with relevant new data?
You could, but it can be expensive and resource intensive. Especially if you need to do it again each time you have new data you want the LLM to “know”. With RAG, the LLM doesn’t actually have to “know” this new information – it just relies on the retriever.
Let’s investigate the parts of RAG a little more:
The Retriever (“Sleuth”)
The retriever’s task is to find document segments matching the input prompt. There are several different ways to accomplish this:
- Keyword search with no deep learning involved. BM25 is a common algorithm for keyword search-based RAG.
- Bi-encoder trained models. Bi-encoder models take in text sequences and output embeddings. Specifically, they generate separate embedding vectors for each document segment and input query. These [document segment, query] embedding pairs are compared to determine relevancy.
- Cross-encoder trained models, which are directly fed a [document segment, query] pair and output a relevancy. Since the outputs of cross-encoders are a more complicated function of the query and documents, it’s not typically possible to store these in a vector database.
More on bi-encoder vs. cross encoder models here.
Bi-encoder models are the usual choice, because
- Bi-encoder models beat keyword search in terms of accuracy.
- Bi-encoder models beat cross-encoder models in terms of compute efficiency. Cross-encoders cannot be naively scaled to large document sets, since each query requires running a forward pass for every document in the set. For bi-encoders, document embedding vectors can be pre-computed and stored in a vector database. However, even using a bi-encoder model for large datasets has a scaling issue, since you still would need to compare every [document segment, query] embedding pair. Because of this, some vector databases offer various forms of “hybrid” keyword and embedding search, or approximate searches that are not guaranteed to return the best matches but run significantly faster.
Example vector databases include:
- Milvus
- Faiss
- Qdrant
- Chromadb
- Weaviate
- Pinecone (closed source)
The Text Generator (“Storyteller”)
The storyteller’s task is to generate text, given the user query and retrieved data. This can be any text generator model of your choosing, with chat or instruction following models giving the best performance:
Chat models: used for multi-stage conversations.
Instruction-following models: used for one-step tasks.
There are tradeoffs in selecting this model, like:
- Larger vs. smaller models: Larger models are generally slower and require more GPU memory, but also give better results.
- “Goodness” of results: some models give better results, either as qualitatively judged by humans or on benchmark tasks. Check out this LMSYS leaderboard and this HuggingFace leaderboard for some example rankings.
Should you finetune your embedding or text generation models?
While it’s feasible to finetune your embedding model, it requires time, expertise, and money. Whether it’s worth it is a question of tradeoffs for your team. If you need excellent retrieval performance on an internal dataset, for example, finetuning might be necessary.
For most standard use cases, pretrained, high-quality embedding models can do the job just fine. For example, you can use OpenAI embeddings, or a model specifically pretrained for embeddings, such as SGPT trained on MSMARCO (MSMARCO, or Microsoft Machine Reading Comprehension, is a dataset derived from real Bing user queries. It includes document and passage ranking data, with information on relevance judgments). This leaderboard is another handy source of alternative embedding models.
As for the text generation LLM, it is far less feasible to finetune, in most standard use cases. Might as well let the pretrained storytellers do what they do best. 😎
How can Determined help?
We recently introduced a new Batch Processing API that is perfect for computing embeddings to store in a vector database. More on that in this blog post. And of course, you can also use Determined’s trusty model training capabilities to finetune your embedding or text generation model if needed.
Conclusion
RAG is easy to build via APIs, reduces LLM hallucinations, and gives you a generally useful chatbot solution. Every company has an internal knowledge base and could likely benefit from RAG somehow. If you liked this, join our Slack Community to stay updated on content! Happy sleuthing 🔎