SEP 11, 2024
Rephrase and Respond (RaR), HuggingFace LLM Leaderboard Updates, and Google's New AGI Framework

November 13, 2023
Lots happened in AI last week! Here are a few things that caught our eye:
- A new prompting technique called Rephrase and Respond (RaR).
- Updates to the HuggingFace Open LLM Leaderboard.
- A new AGI Framework paper published by Google.
OpenAI also hosted DevDay on November 6th, which you can read about here.
1) A brand new prompting technique called Rephrase and Respond (RaR) was published by Deng et al from UCLA.
This technique improves LLM performance, especially when used together with Chain of Thought (CoT) prompting. For a full refresher on basic prompting techniques, check out our blog post on LLM prompting.
How does RaR work? Simply adding “Rephrase and expand the question, and respond.” to the prompt, tells the LLM to rearticulate the user question, and then respond, all in one shot. This figure from the paper illustrates this concept well:

There is also a two-step version of this technique outlined in the paper, called Two-step RaR: -Rephrase the Question and Respond to the Rephrased Question. First, a rephrasing LLM rephrases the question, and then the original and rephrased question are concatenated into a final prompt, to which a Responding LLM responds with a final answer. The Rephrasing and Responding LLMs can be the same or different LLM. Interestingly, the paper mentions that if a stronger Rephrasing LLM, like GPT-4, is used, it can help the performance of weaker Responding LLMs, like Vicuna.

1) HuggingFace Open LLM Leaderboard Updates
3 new benchmarks from the EleutherAI LM Evaluation Harness were added to the HuggingFace Open LLM leaderboard:
-
Drop – English reading comprehension benchmark.
-
GSM8k – multi step grade school mathematical reasoning benchmark.
-
Winogrande – commonsense reasoning benchmark based on “fill-in the blank” type questions.
These benchmarks measure the generative ability of LLMs, while previous benchmarks on the HuggingFace leaderboard focused on measuring the performance on multiple choice Q/A tasks - making this a hugely important step keeping LLM evaluation current.
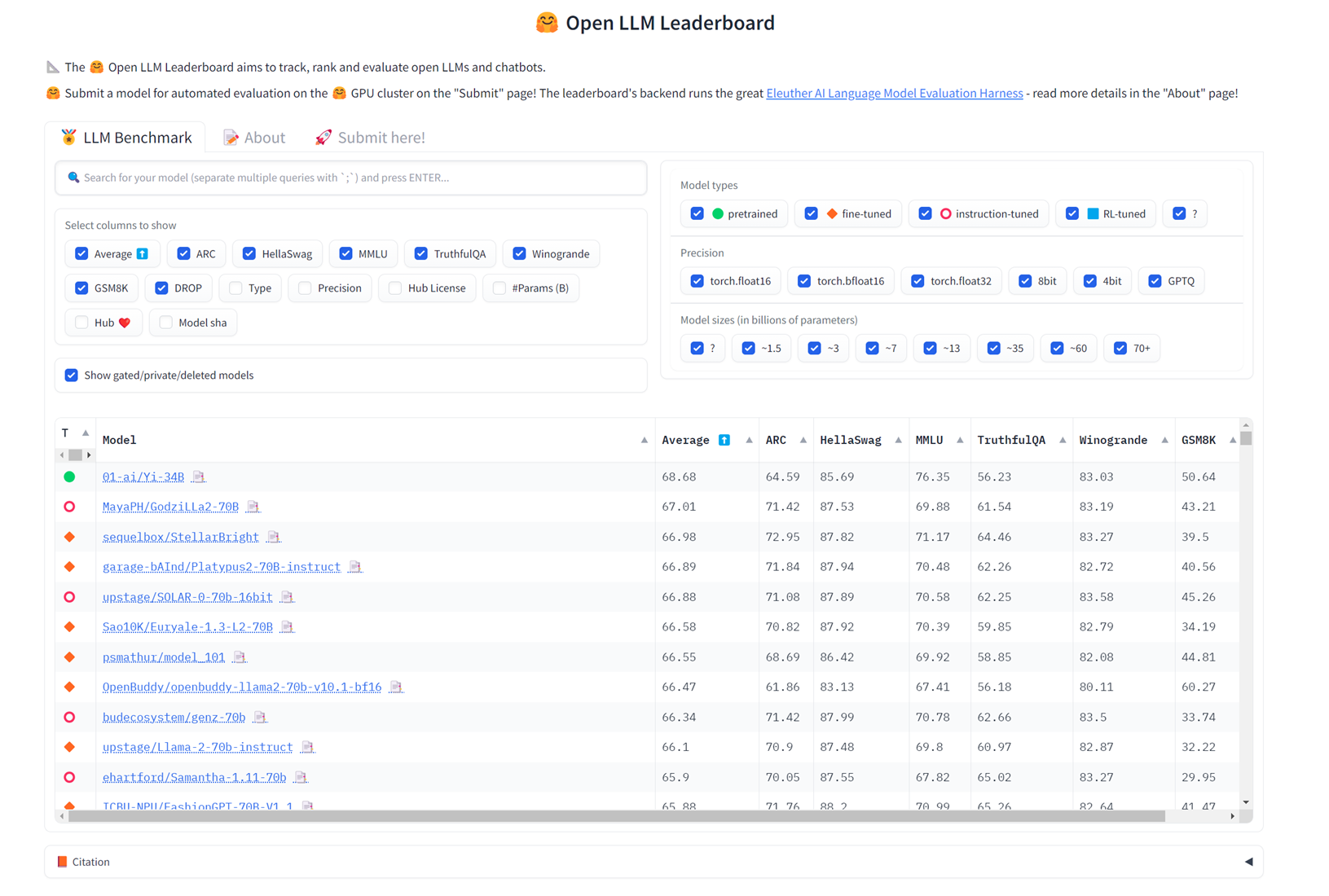
Check out the updated leaderboard here. At the time of writing, a pretrained Yi series model, Yi-34B, outperforms all other pretrained, fine-tuned, instruction-tuned, and RL-tuned models on the tasks selected:
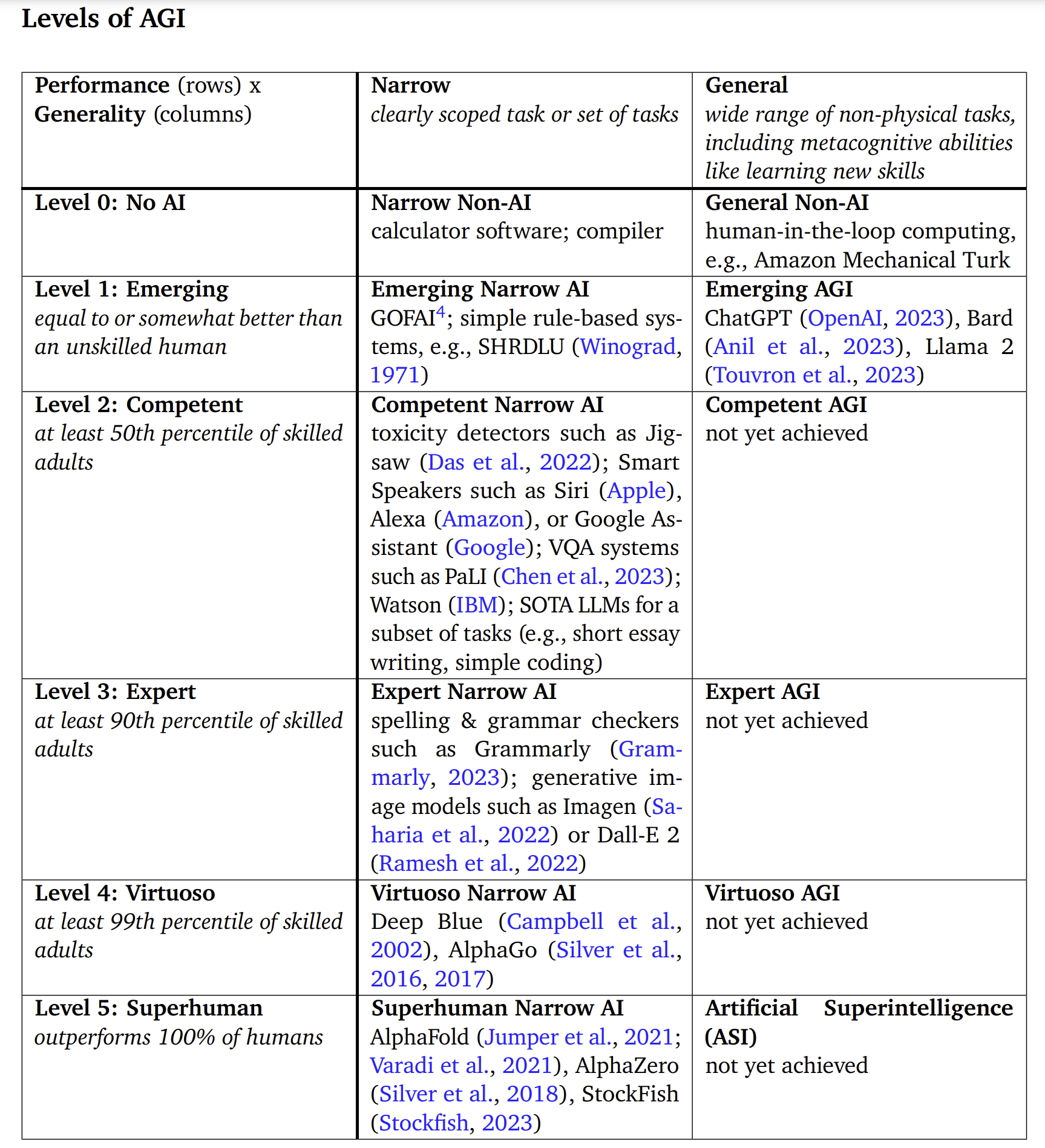
3) Google DeepMind releases AGI framework
Until now, there was no common framework to facilitate conversations about AGI and where LLMs fall in the spectrum. According to Google, today’s LLMs fall into the Level 1: Emerging (General) category. Check out the paper here. Here’s the chart that sums it up:
As always, stay up to date in our Slack Community!