SEP 11, 2024
Self-Discover, Grandmaster-Level Chess without Search, and DeepSeekMath7B

February 12, 2024
Here’s what caught our eye last week:
SELF-DISCOVER: Large Language Models Self-Compose Reasoning Structures
Using the right prompting technique can enable an LLM to perform better on certain tasks. For example, Chain-of-Thought Prompting can be useful when asking an LLM to solve a math problem, as it encourages the LLM to explicitly reason through the problem, leaving less room for hallucination. These prompts serve as a sort of “reasoning structure” for how the model should go about solving the problem.
But what if there was a way to develop specialized reasoning structures for specific problems? This paper describes a framework for having a large language model do just that: create a custom “reasoning structure” - sort of like an elementary school worksheet - for a new problem, and then utilize that reasoning structure to solve the problem. Here’s an example:
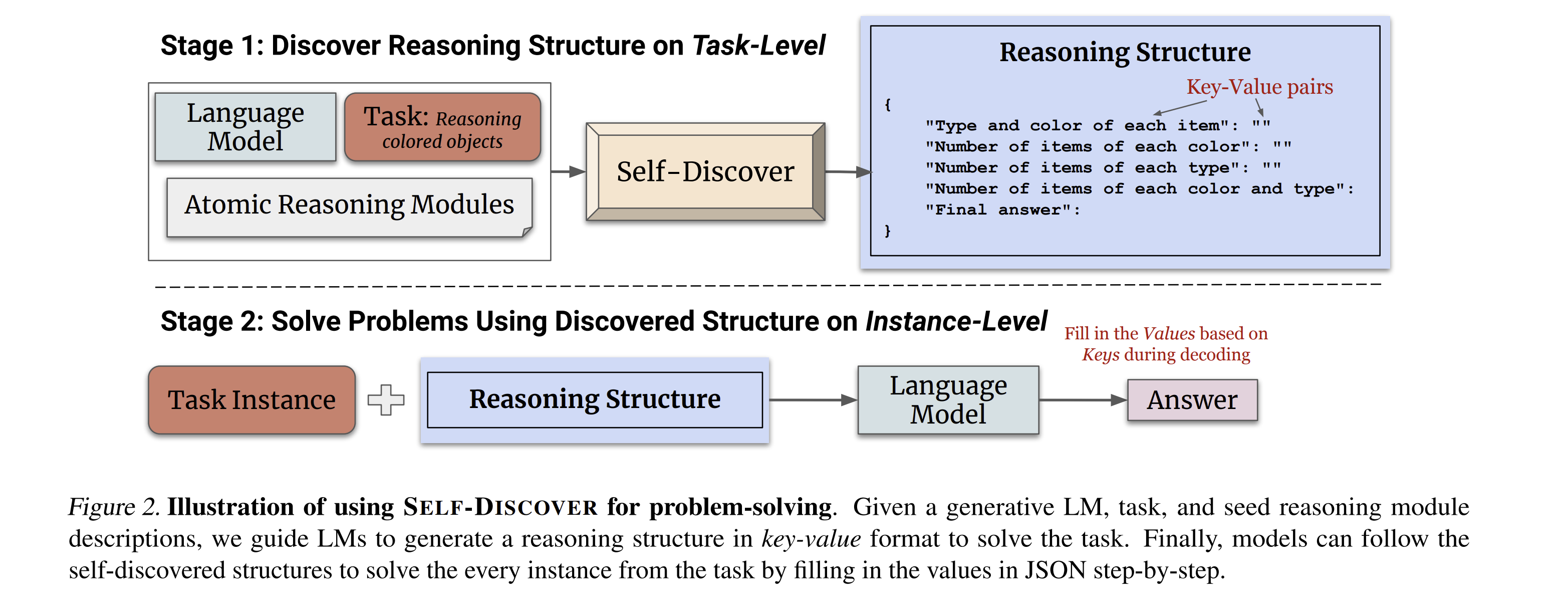
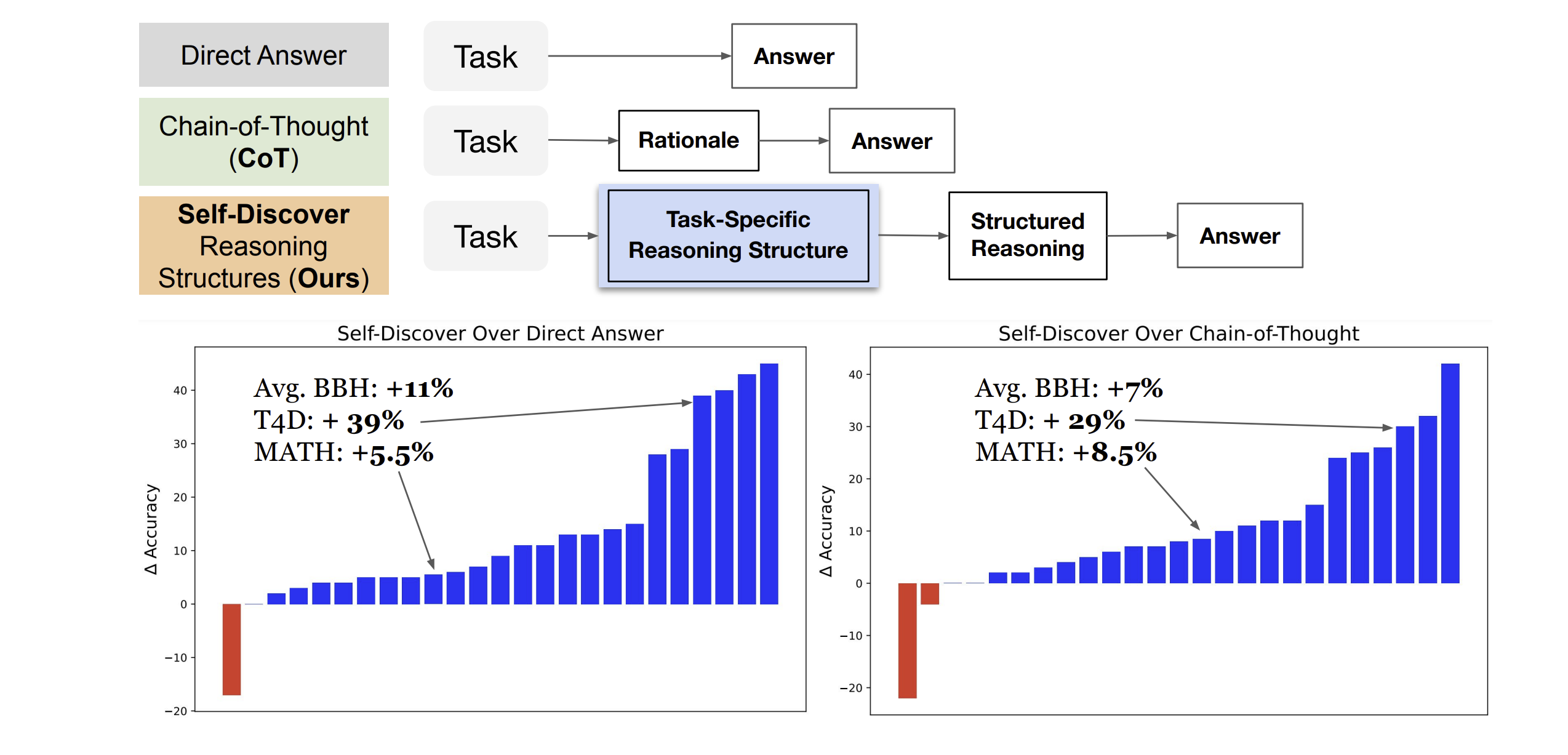
Here’s the performance improvement when using Self-Discover as compared to Chain-of-Thought prompting and direct answering:
Grandmaster-Level Chess Without Search
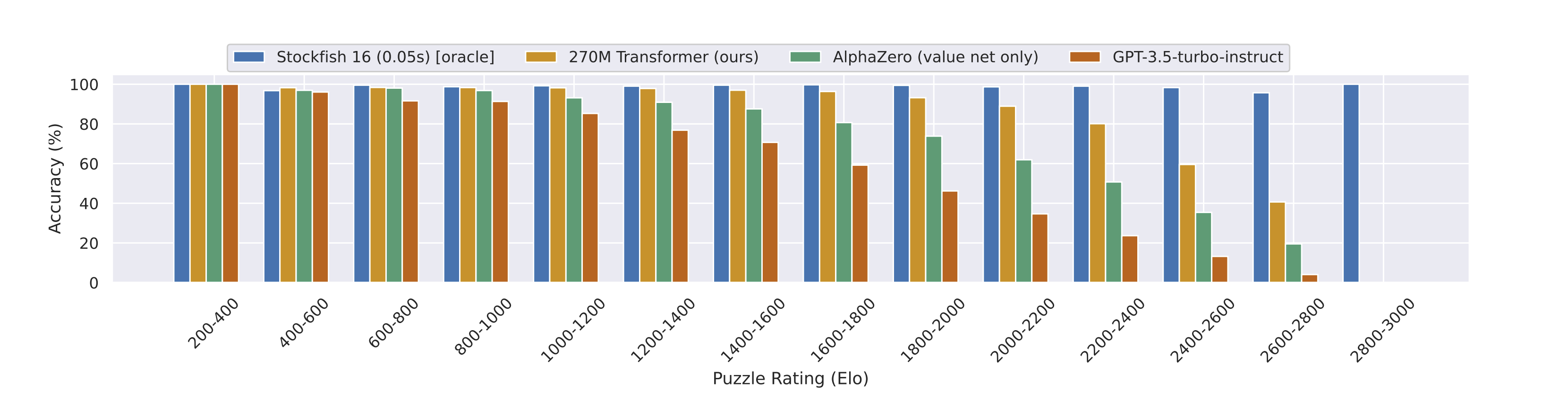
Transformer models are insanely powerful, and this is no better illustrated than by a story of how training a 270M parameter transformer model on chess data performs better than past state-of-the-art models which use complex heuristics and search.
This model is trained using supervised learning on 10 million chess games, in 3 different prediction settings:
Action-Values (AV): The expected win probabilities for each possible move.
State-Values (SV): The win probability of the board.
Behavioral Cloning (BC): The behavior of Stockfish, currently the strongest chess engine available to the public.
This model outperforms GPT3.5-Turbo and AlphaZero. Check out the results on different puzzle ratings below (if you’re curious about the meaning of Elo rating numbers, check out this article):
DeepSeekMath 7B
Tackling math problems is a tough challenge for LLMs, due to the complex and precise nature of math language. Enter DeepSeekMath 7B, an upgraded version of DeepSeek-Coder-Base-v1.5 7B. DeepSeekMath 7B was trained on a whopping 120 billion math-related tokens from the internet, along with a sprinkle of everyday language and coding knowledge. The result? DeepSeekMath 7B scored an impressive 51.7% on the MATH benchmark, on-par with Gemini-Ultra and GPT-4.
What resulted in its success are two main strategies:
1) A meticulously curated data pipeline to source math data from the Common Crawl dataset.
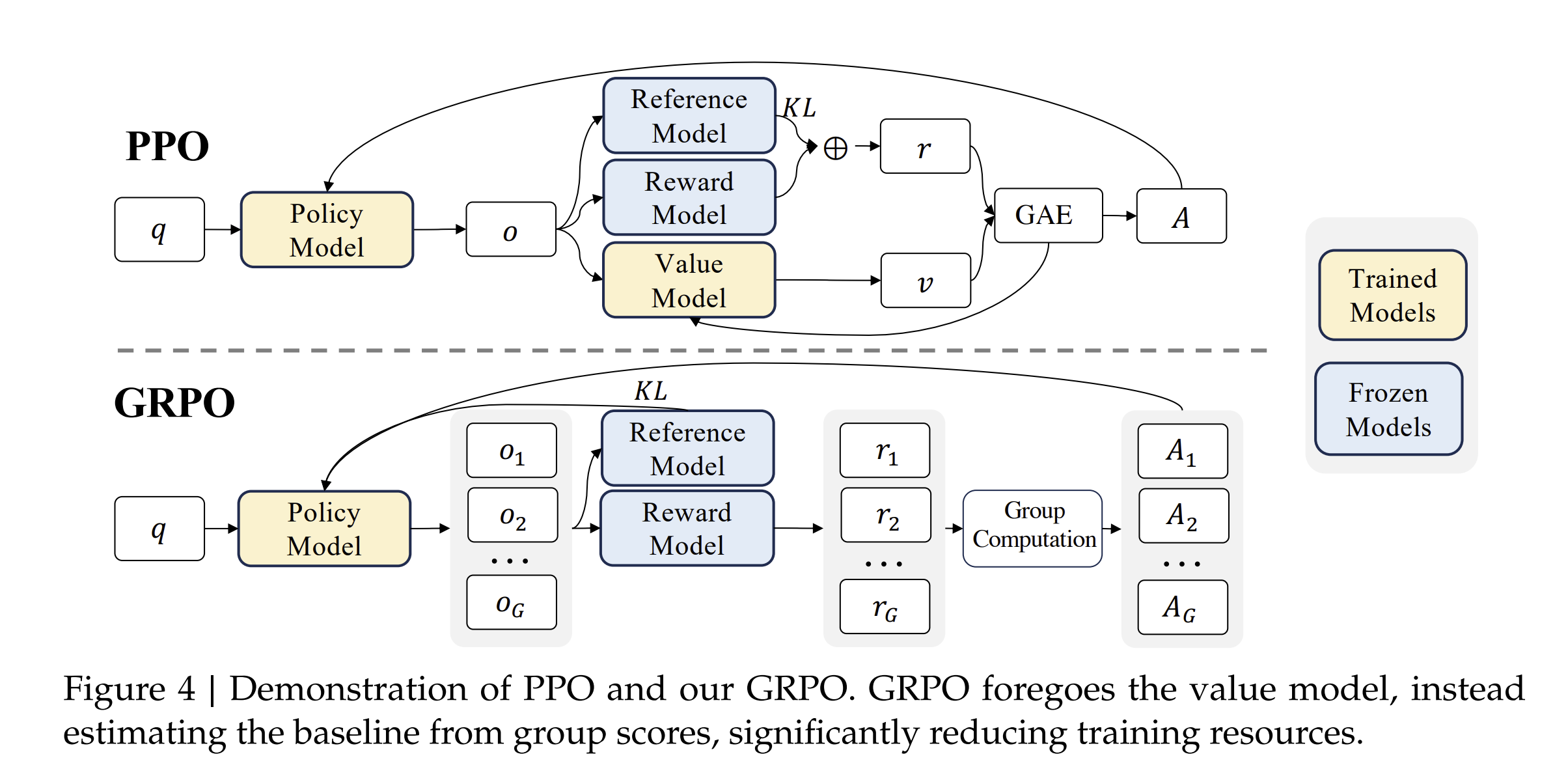
2) Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO).
Here’s a quick rundown of GRPO:
PPO is a reinforcement learning technique. It uses a value model which informs a policy model, over time. GRPO is a new twist on this method - it removes the value model, and instead uses the average outcome of groups of actions to inform how the policy model should adjust, making GRPO much more efficient than PPO.
Other
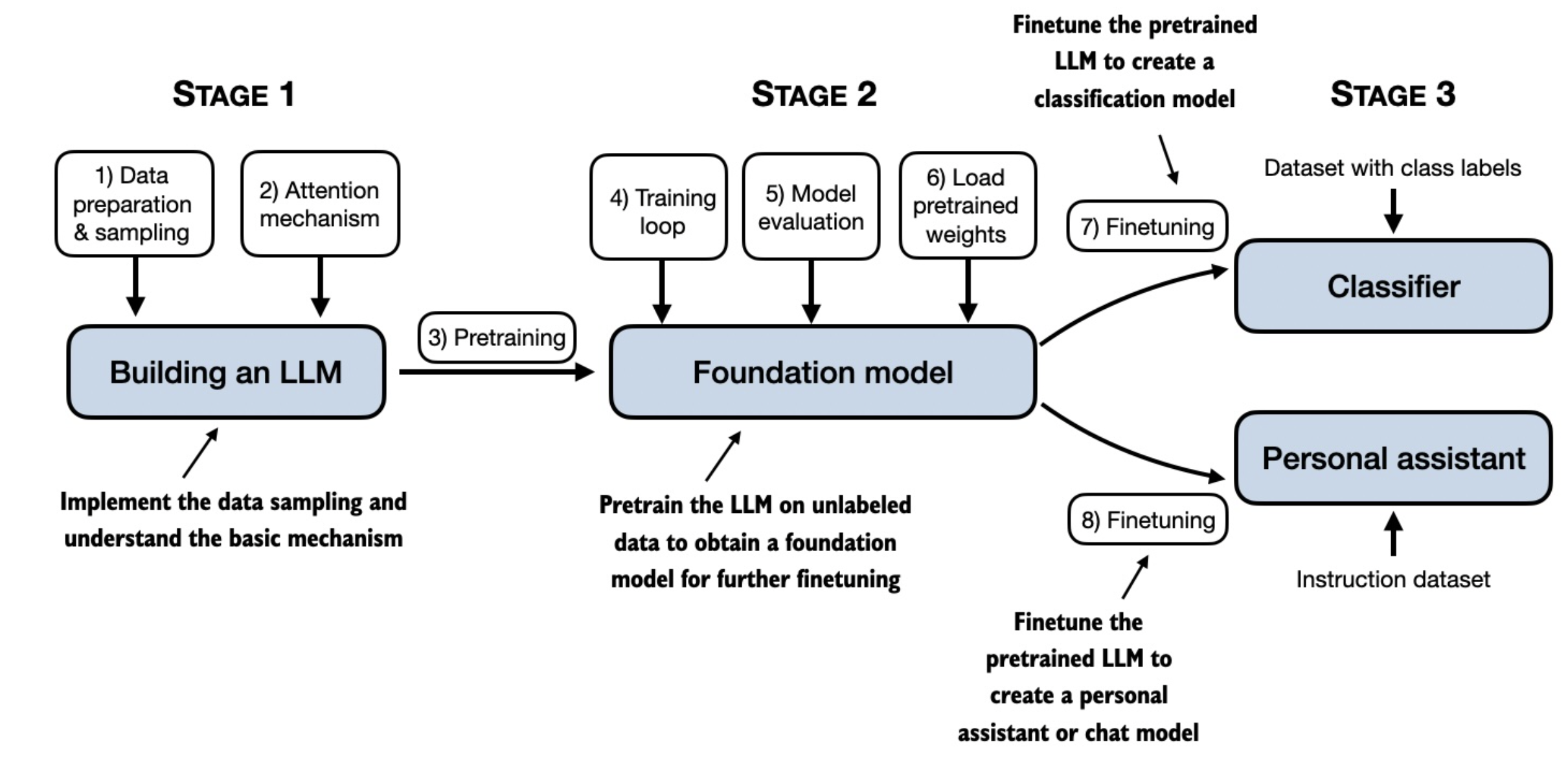
If you want to learn how to train an LLM from scratch, check out this awesome GitHub repo:
Stay up to date
Interested in future weekly updates? Stay up to date by joining our Slack Community!