SEP 11, 2024
Generative Powers of 10, SeamlessExpressive, Mistral 8x7B, and Magicoder

December 11, 2023
Here’s what caught our eye last week in AI.
1) Generative Powers of Ten:
This method enables a pretrained text model to achieve extreme semantic zooms into a scene (called “super resolution”), like from a galaxy all the way down to the surface of an alien planet. It’s cleverly named after the documentary series Powers of Ten (1977), which shows the scale of the Universe, expanding in and out by factors of 10.

How does it work?
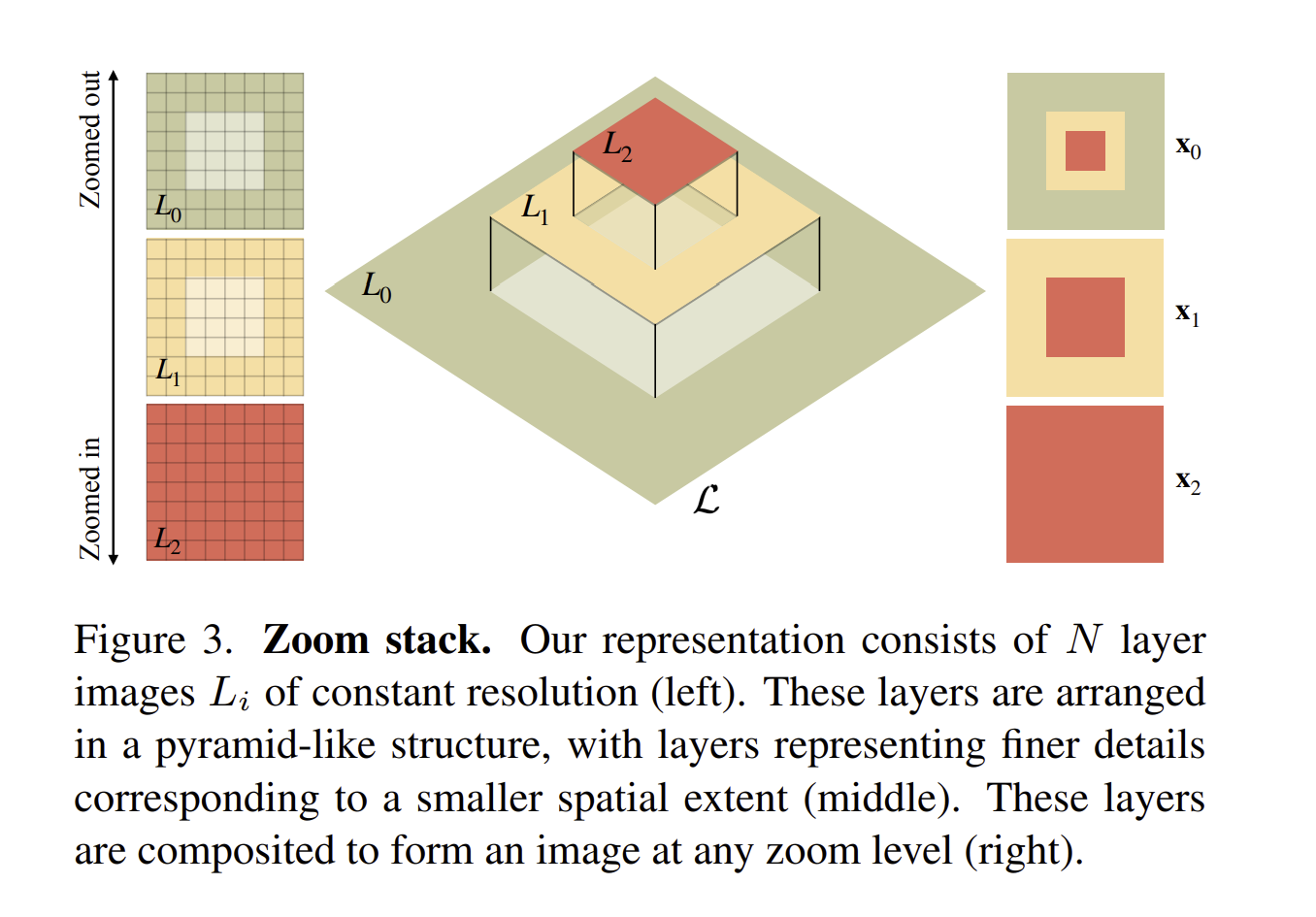
This technique involves creating a series of images that show the same scene at varying zoom levels. These zoom levels follow a geometric progression (commonly set to 2 or 4), meaning each subsequent image is a closer zoom on the scene.
The images are created using a pre-trained text-to-image diffusion model, which interprets a series of text prompts corresponding to each zoom level.
Since each image is not going to be perfectly consistent with its neighboring images across different zoom levels, they need to be integrated together into something called a “zoom stack” to ensure consistency.
The zoom stack is a key component of this method that gets updated by consolidating multiple diffusion estimates together using multi-scale joint sampling. The result is a smoothly integrated sequence of images that allows for rendering an image at any given zoom level, making for a seamless and continuous zoom experience on the depicted scene. Read more details in the paper.
2) SeamlessExpressive
On November 30th, Meta released SeamlessExpressive, a new language translation model based on SeamlessM4T v2. SeamlessM4T, a foundational multilingual and multitask model, was released earlier this year. SeamlessExpressive is actually one of a family of two models based on Seamless MT4 v2, including SeamlessStreaming, which is built for real time translation.
SeamlessExpressive is able to preserve “vocal styles and prosody” (basically tonality, voice, and expressiveness) - of the original speaker when doing video translation. It’s pretty amazing. Check out the demo examples here. You can even try it out for yourself!
3) Mixtral of Experts
Mistral AI released a new open source model via just a torrent link a few days ago, and just 12 hours ago announced it on their website, with official evaluation results, and an official name - “Mixtral of Experts”.
The AI community got to work lightning fast on 8x7B, though:
- Check out these HumanEval code benchmark results shared via X.
- Try it out here.
4) And More…
-
Google releases Gemini, the first model to outperform human experts on MMLU (Massive Multitask Language Understanding). Read more about Gemini here. If you’re unfamiliar with MMLU, we covered it in our last weekly update.
-
Magicoder was released last week. This is a family of models that outperform state of the art code generation models, with the largest models having only 7 billion parameters. They’re trained on synthetic instruction data using OSS-Instruct, a novel method for training LLMs to generate high quality code snippets.
Stay up to date
Interested in future weekly updates? Stay up to date by joining our Slack Community!