SEP 11, 2024
How Multimodal LLMs Work

January 17, 2024
Large Language Models (LLMs) have shown an impressive ability to understand text. But there are many cases where we’d like LLMs to understand more than just text. We might want them to receive or generate multiple modalities of data, like text, images, and audio. LLMs with this capability are called multimodal LLMs, and in this post, we’ll give a high-level overview of three multimodal LLMs in the vision-language domain. As we’ll see, all three LLMs have the following components in common:
- A vision-only model.
- A text-only model (the LLM).
- One or more components that convert the output of the vision model into a format that can be fed into the LLM.
Let’s dive in.
Flamingo
Flamingo is a multimodal LLM that was presented in 2022. Here’s how the vision and language components work:
- The vision encoder converts images or videos into embeddings (lists of numbers). These embeddings vary in size depending on the dimensions of the input images, or the lengths of the input videos, so another component called the Perceiver Resampler converts these embeddings to a common fixed length.
- The language model takes in text, and the fixed-length vision embeddings from the Percever Resampler. The vision embeddings are used in multiple “cross-attention” blocks, which learn to weigh the importance of different parts of the vision embedding, given the current text. Read more about cross-attention here.
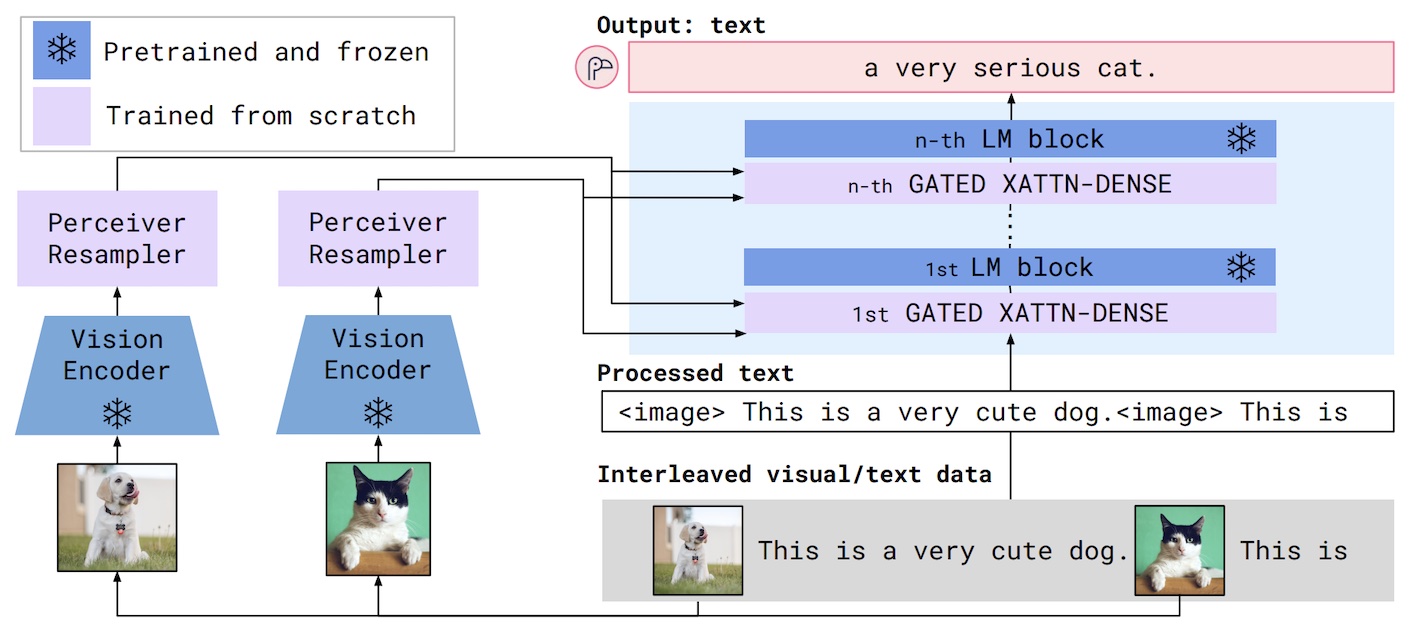
Training occurs in three steps:
- The vision encoder is pretrained using CLIP (see the next section for an explanation). CLIP actually trains both a vision encoder and a text encoder, so the text encoder from this step is discarded.
- The language model is a Chinchilla model pretrained on next-token prediction, i.e. predicting the next group of characters given a series of previous characters. This is how most LLMs like GPT-4 are trained. You might hear this type of model referred to as “autoregressive”, which means the model predicts future values based on past values.
- In the third stage, untrained cross-attention blocks are inserted into the language model, and an untrained Perceiver Resampler is inserted between the vision encoder and the language model. This is the complete Flamingo model, but the cross-attention blocks and the Perceiver Resampler still need to be trained. To do this, the entire Flamingo model is used to compute tokens in the next-token prediction task, but the inputs now contain images interleaved with text. Furthermore, the weights of the vision encoder and the language model are frozen. In other words, only the Perceiver Resampler and cross-attention blocks are actually updated and trained.
After training, Flamingo is able to perform a variety of vision-language tasks, including answering questions about images in a conversational format.

What is CLIP?
As mentioned in the previous section, Flamingo uses CLIP in its pretraining stage. CLIP is not a multimodal LLM. Instead, it is a training methodology that produces separate vision and text models with powerful downstream capabilities. CLIP stands for Contrastive Language-Image Pre-training, and it is conceptually very simple:
- The model architecture consists of an image encoder and text encoder. The image encoder converts images to embeddings (lists of numbers), and the text encoder converts text to embeddings.
-
The two encoders are trained on batches of image-text pairs, in which the text describes the image. The encoders are trained such that:
- For each image-text pair, the image and text embeddings are “close” to each other.
- For all non-matching image-text pairs, the image and text embeddings are far from each other.
Note that there are many ways to measure the distance between two embeddings. Some common ways are Euclidean distance and cosine similarity. CLIP uses the latter.
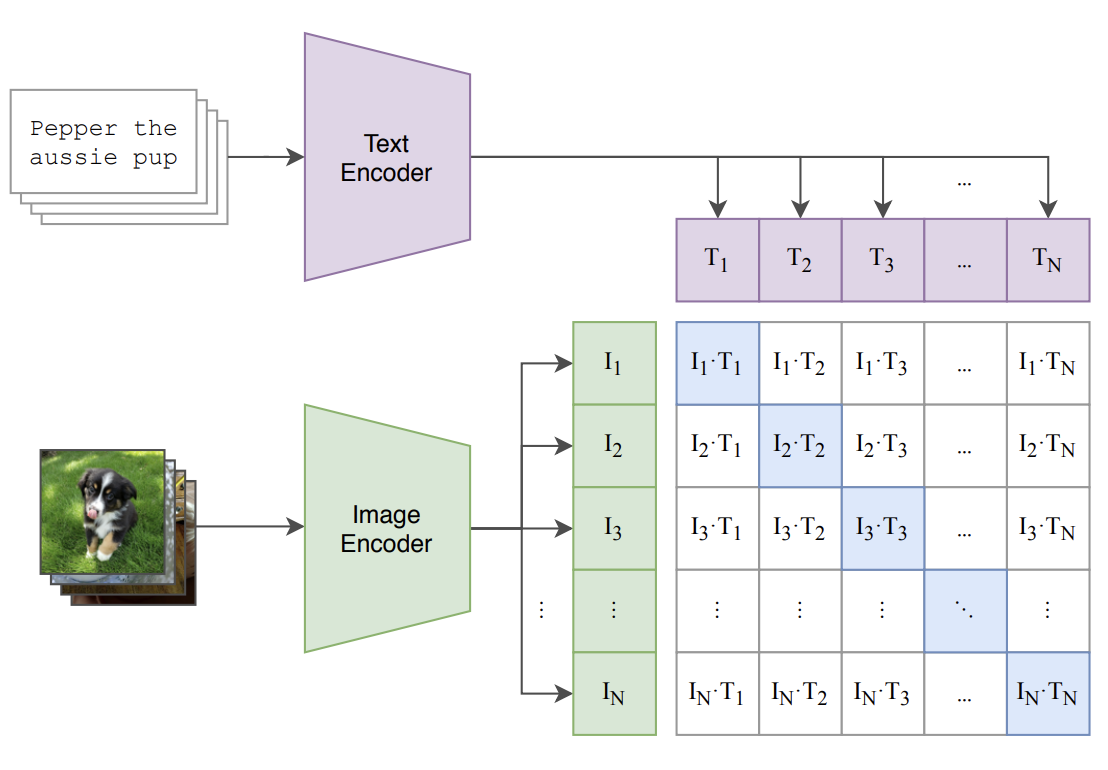
At a high level, CLIP learns a joint image-text embedding space, which basically means that the similarity between images and text can be directly computed. It turns out that training models with this goal makes them generally very useful, including in the context of multimodal LLMs.
BLIP-2
BLIP-2 is a multimodal LLM that was released in early 2023. Like Flamingo, it contains a pretrained image encoder and LLM. But unlike Flamingo, both the image encoder and LLM are left untouched (after pretraining).
To connect the image encoder to the LLM, BLIP-2 uses a “Q-Former”, which consists of two components:
- The visual component receives a set of learnable embeddings and the output of the frozen image encoder. As done in Flamingo, the image embeddings are fed into cross-attention layers.
- The text component receives text.
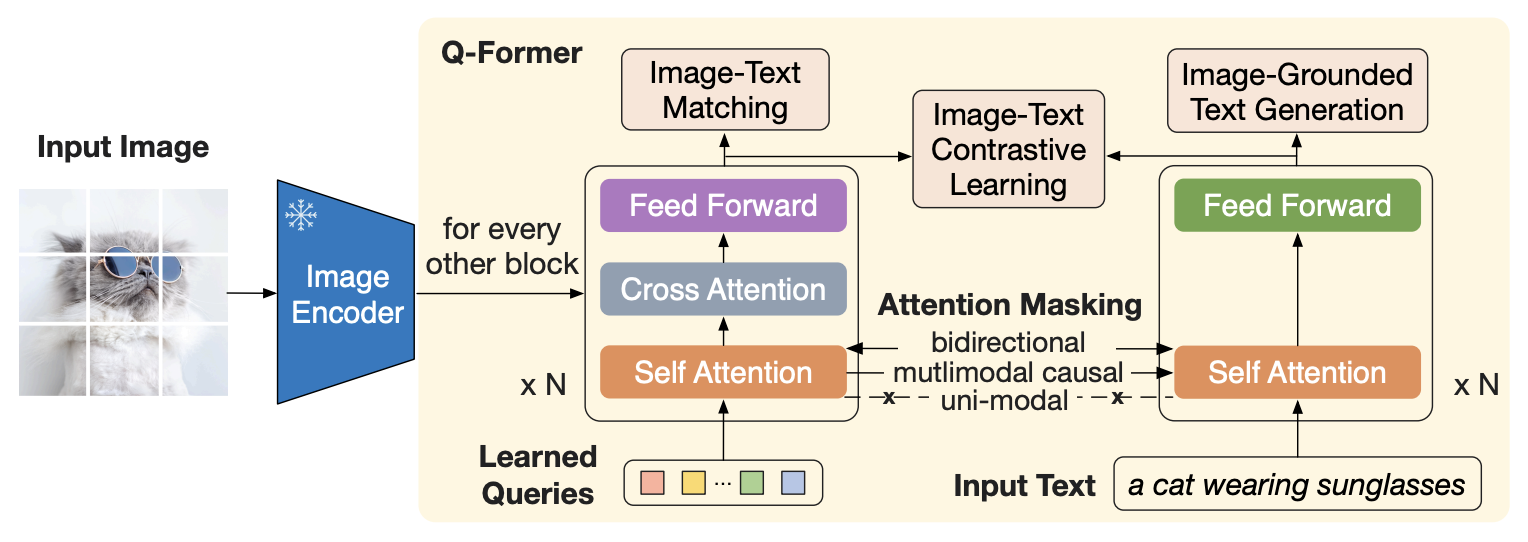
Training BLIP-2 occurs in two stages:
-
In stage 1, the two components of the Q-Former are trained on three objectives, which actually originate from the BLIP-1 paper:
- Image-text contrastive learning (similar to CLIP, but with some subtle differences).
- Image-grounded text generation (generating captions of images).
- Image-text matching (a binary classification task where for each image-text pair, the model has to answer 1 to indicate a match and 0 otherwise).
-
In stage 2, the full model is constructed by inserting a projection layer between the Q-Former and the LLM. This projection layer transforms the Q-Former’s embeddings to have lengths that are LLM-compatible. The full model is then tasked with describing input images. During this stage, the image encoder and LLM remain frozen, and only the Q-Former and projection layer are trained.

In the paper’s experiments, they use a CLIP-pretrained image encoder and either OPT or Flan-T5 for the LLM. The experiments show that BLIP-2 can outperform Flamingo on various visual question-answering tasks, but with a fraction of the trainable parameters. This makes it easier and more cost-effective to train.
LLaVA
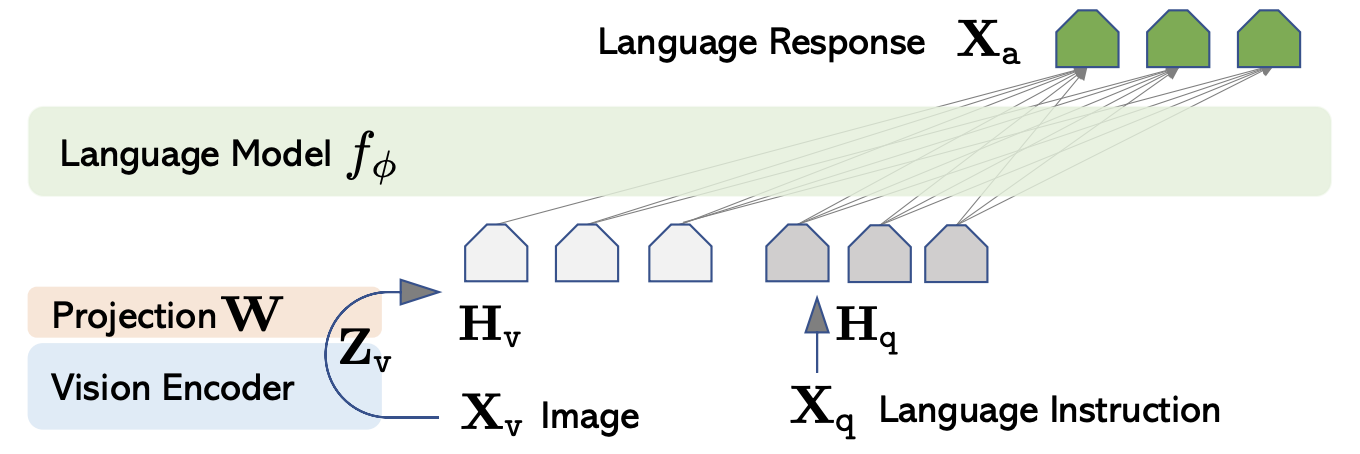
LLaVA is a multimodal LLM that was released in 2023. The architecture is quite simple:
- The vision encoder is pretrained using CLIP.
- The LLM is a pretrained Vicuna model.
- The vision encoder is connected to the LLM by a single projection layer.
Note the simplicity of the component between the vision encoder and the LLM, in contrast with the Q-Former in BLIP-2, and the Perceiver Resampler and cross-attention layers in Flamingo.
There are two training stages:
- In stage 1, the training objective is image captioning. The vision encoder and LLM are frozen, so only the projection layer is trained.
- In stage 2, the LLM and projection layer are finetuned on a partially-synthetic instruction-following dataset. It’s partially synthetic because it’s generated with the help of GPT-4.
The authors evaluate LLaVA as follows:
- They use GPT-4 to evaluate the quality of LLaVA’s responses on a partially synthetic dataset. Here, LLaVA scores 85% relative to GPT-4.
- They use standard evaluation metrics on a visual question answering dataset called ScienceQA. Here, a finetuned LLaVA outperforms GPT-4.
LLaVA illustrates that a simple architecture can achieve excellent results when trained on partially synthetic data.
Summary
In this post, we briefly covered three important multimodal LLMs, plus CLIP.
Interested in learning more about LLMs? Check out our posts on LLM Prompting and Retrieval Augmented Generation (RAG).
And join our Slack Community to stay updated on our latest content!