Blogs
Weekly updates from our team on topics like large-scale deep learning training, cloud GPU infrastructure, hyperparameter tuning, and more.
AUG 21, 2023
How to View Epoch-Based Metrics in the WebUI
Analyze and visualize your model’s training progress and validation performance over multiple epochs.
JUL 25, 2023
Use Batch Inference in Determined Part 1: Text Embedding Computation
Introducing a new Batch Processing API for batch inference use cases!
FEB 20, 2023
Determined AI Hackathon – Now Open!
Use Determined to produce cool deep learning experiments and earn fame and fortune!
NOV 29, 2022
Intro to Determined: A First Time User's Guide
If you want to learn how to use Determined but don’t know where to start, this guide is for you!

OCT 31, 2022
Personalizing Stable Diffusion with Determined
Stable Diffusion is the latest deep learning model to produce eye-popping art. With Determined AI, you can easily generate personalized pieces with Stable Diffusion through distributed fine-tuning.

AUG 10, 2022
Getting Started With Determined: A First-Time User’s Experience, Part Two
Using our setup from Part 1 of this series, let’s dive into training an iris classification model on Determined with advanced deep learning capabilities!

JUN 22, 2022
Training Arbitrary Models Made Easy With Core API
Seamlessly integrate arbitrary machine learning models and training loops into the Determined model training platform with Core API.
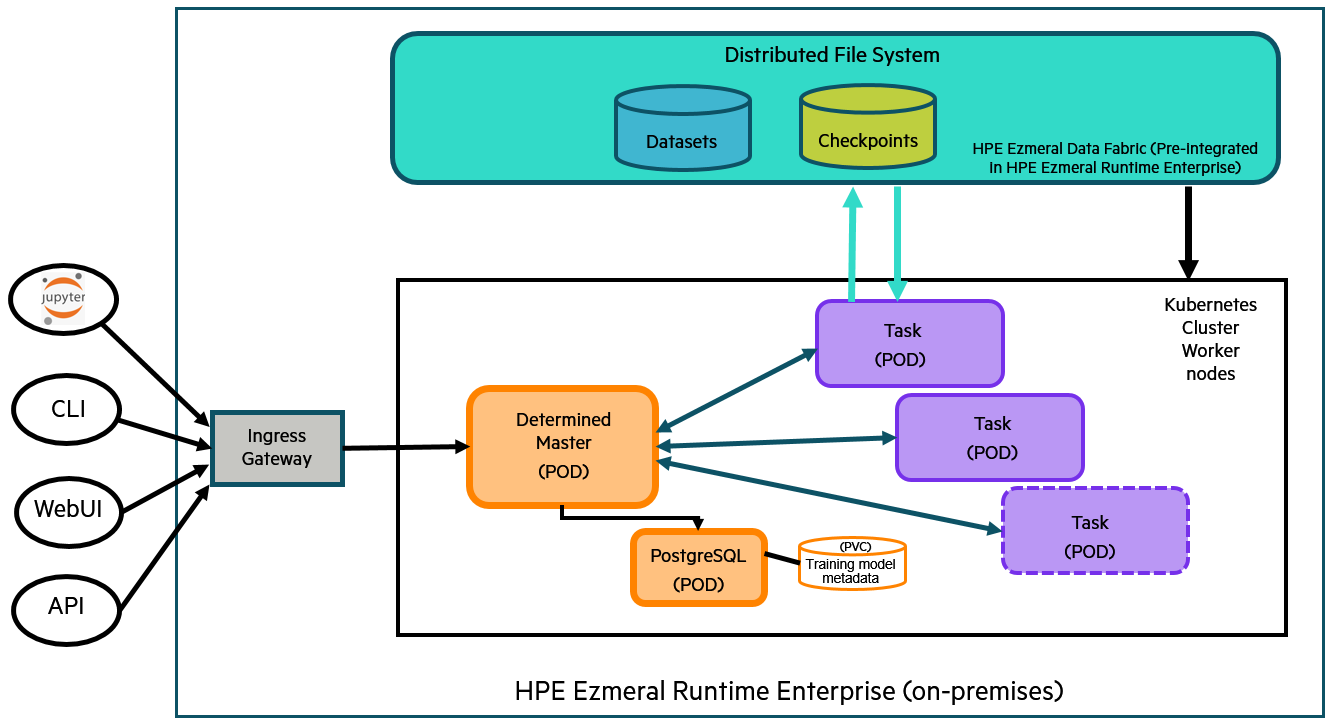
MAY 11, 2022
Getting Started With Determined: A First-Time User’s Experience
Read a comprehensive review of a first-time user’s experience getting started with Determined alongside HPE Ezmeral Runtime Enterprise and Kubernetes.

MAR 08, 2022
Maximize Your Jupyter Notebook Experience With Determined
Use Jupyter Notebooks and Determined together to more easily manage deep learning experiments.

MAY 13, 2021
Easier NLP training with Metaflow and Determined
Bring your deep learning projects from research to reality by using Metaflow’s real-life data science framework with Determined’s deep learning training platform.