Blogs
Weekly updates from our team on topics like large-scale deep learning training, cloud GPU infrastructure, hyperparameter tuning, and more.

DEC 11, 2023
Generative Powers of 10, SeamlessExpressive, Mistral 8x7B, and Magicoder
Here’s what happened in AI last week.

DEC 06, 2023
The Determined Python SDK
Programatically manage large-scale machine-learning experiments in Python.

DEC 04, 2023
Visual Anagrams, Adversarial Diffusion Distillation, and A New Multi Modal Benchmark
Here’s what happened in AI last week.

NOV 27, 2023
Stable Video Diffusion, Lookahead Decoding, and ZipLoRA
Here’s what happened in AI last week.


NOV 20, 2023
Emu Video, LLM Decontaminator, Faster SAM, and a Genome LLM Review Paper
Here’s what happened in AI last week.
NOV 13, 2023
Rephrase and Respond (RaR), HuggingFace LLM Leaderboard Updates, and Google's New AGI Framework
Here’s what happened in AI last week.
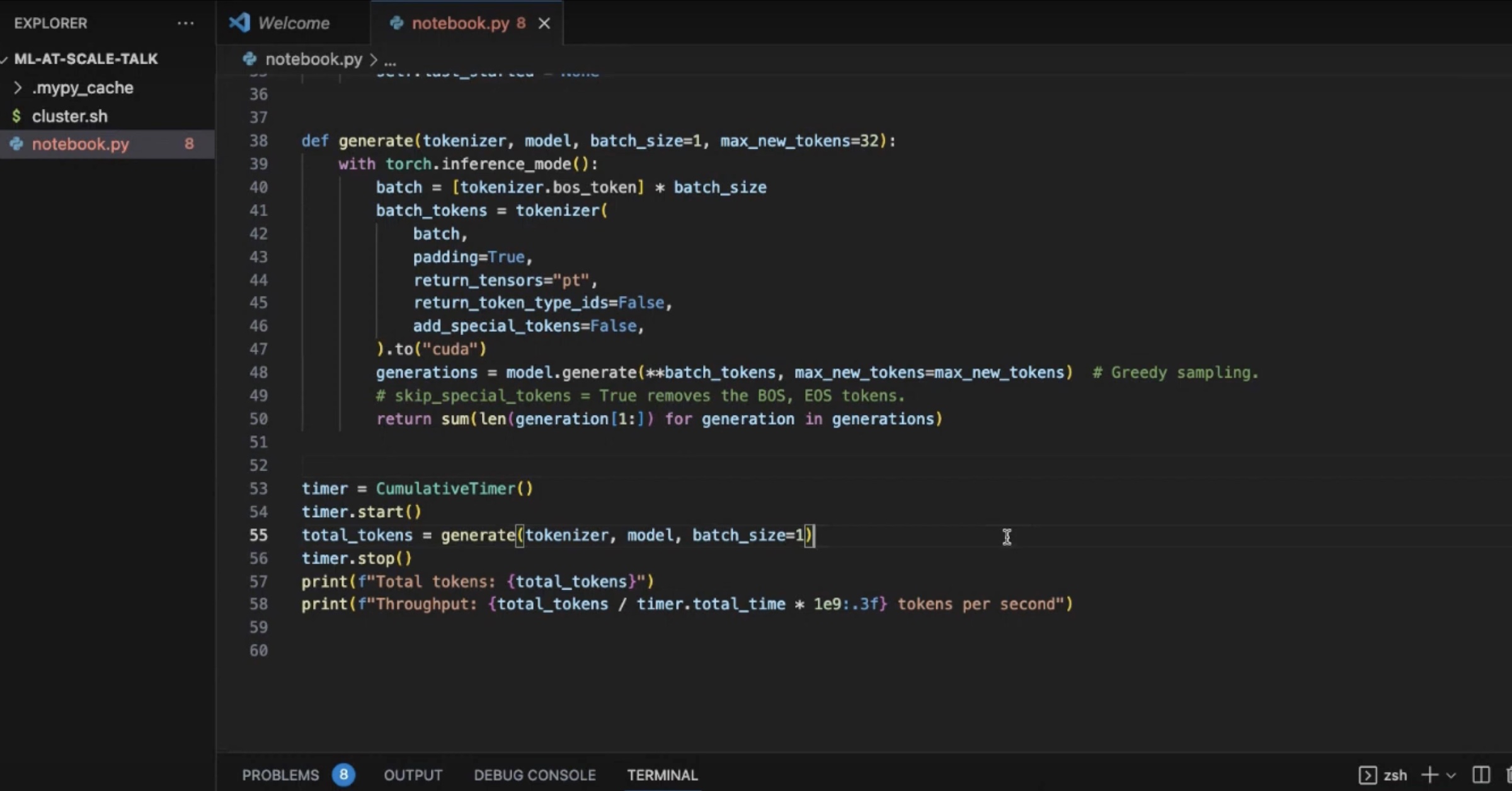
NOV 08, 2023
New video demo: LLM Batch Inference with Determined
Optimize inference using Determined’s Core API + Hugging Face Transformers
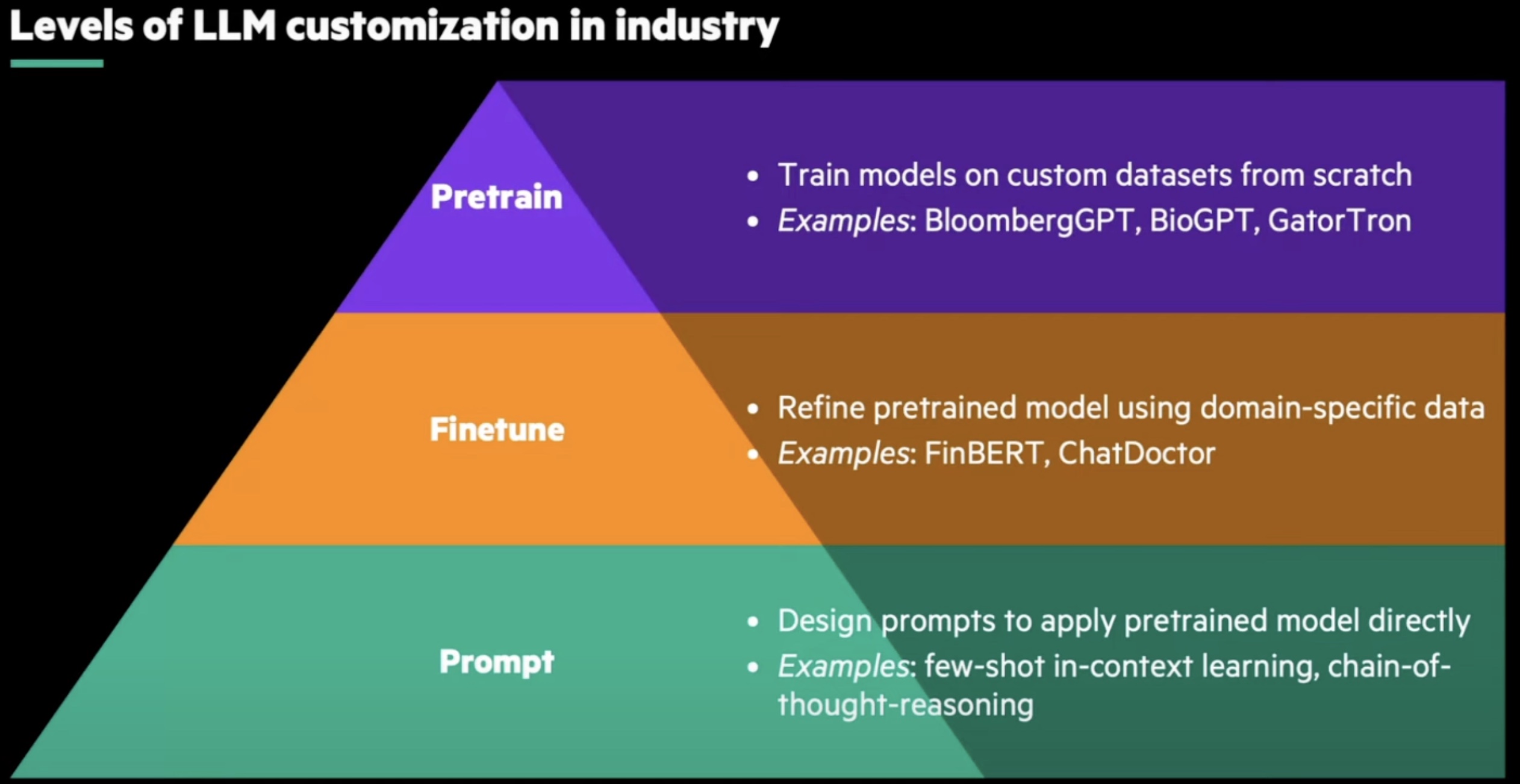
NOV 01, 2023
New video: Harnessing the Power of LLMs in Industry
Learn about various strategies, from simple prompting to advanced pretraining, that enable the deployment of language models to specialized domains.

OCT 30, 2023
LLM Prompting: The Basic Techniques
A gentle introduction to large language model prompting methods and terminology.