Blogs
Weekly updates from our team on topics like large-scale deep learning training, cloud GPU infrastructure, hyperparameter tuning, and more.
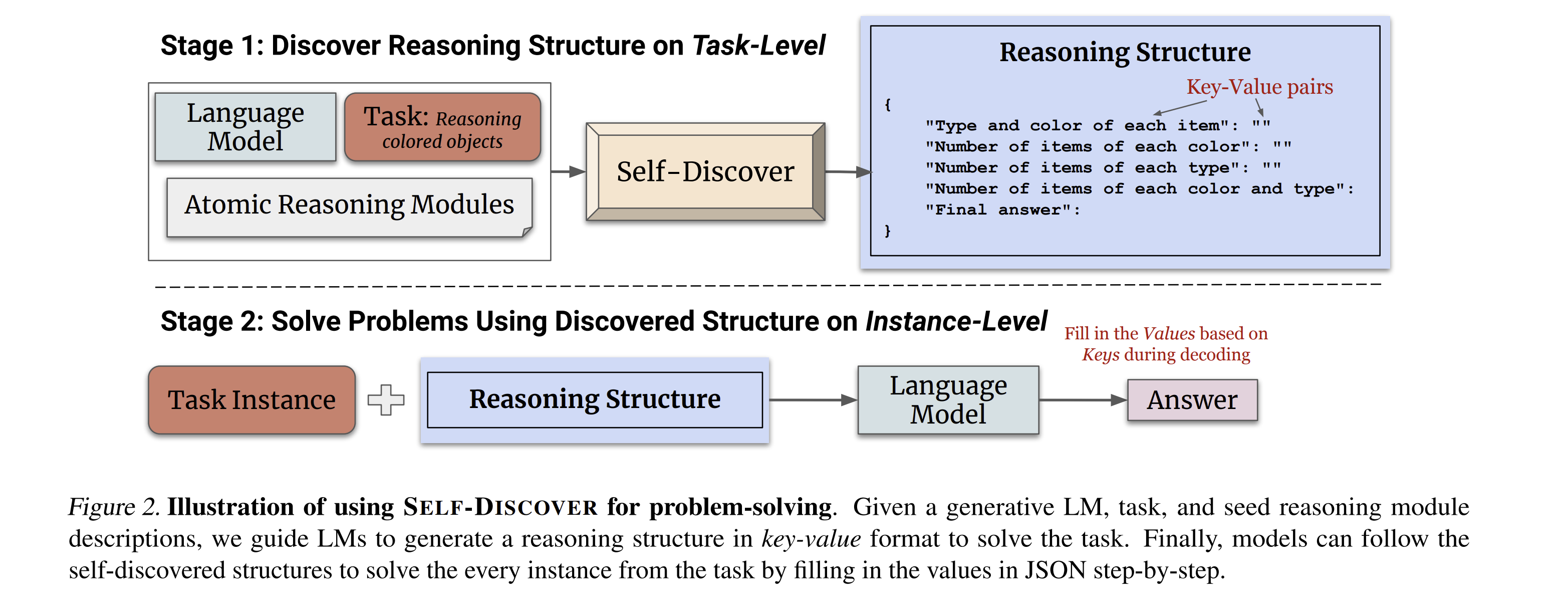
FEB 12, 2024
Self-Discover, Grandmaster-Level Chess without Search, and DeepSeekMath7B
Short summaries of self composing reasoning structures, LLMs for math and chess, plus other highlights from the week.
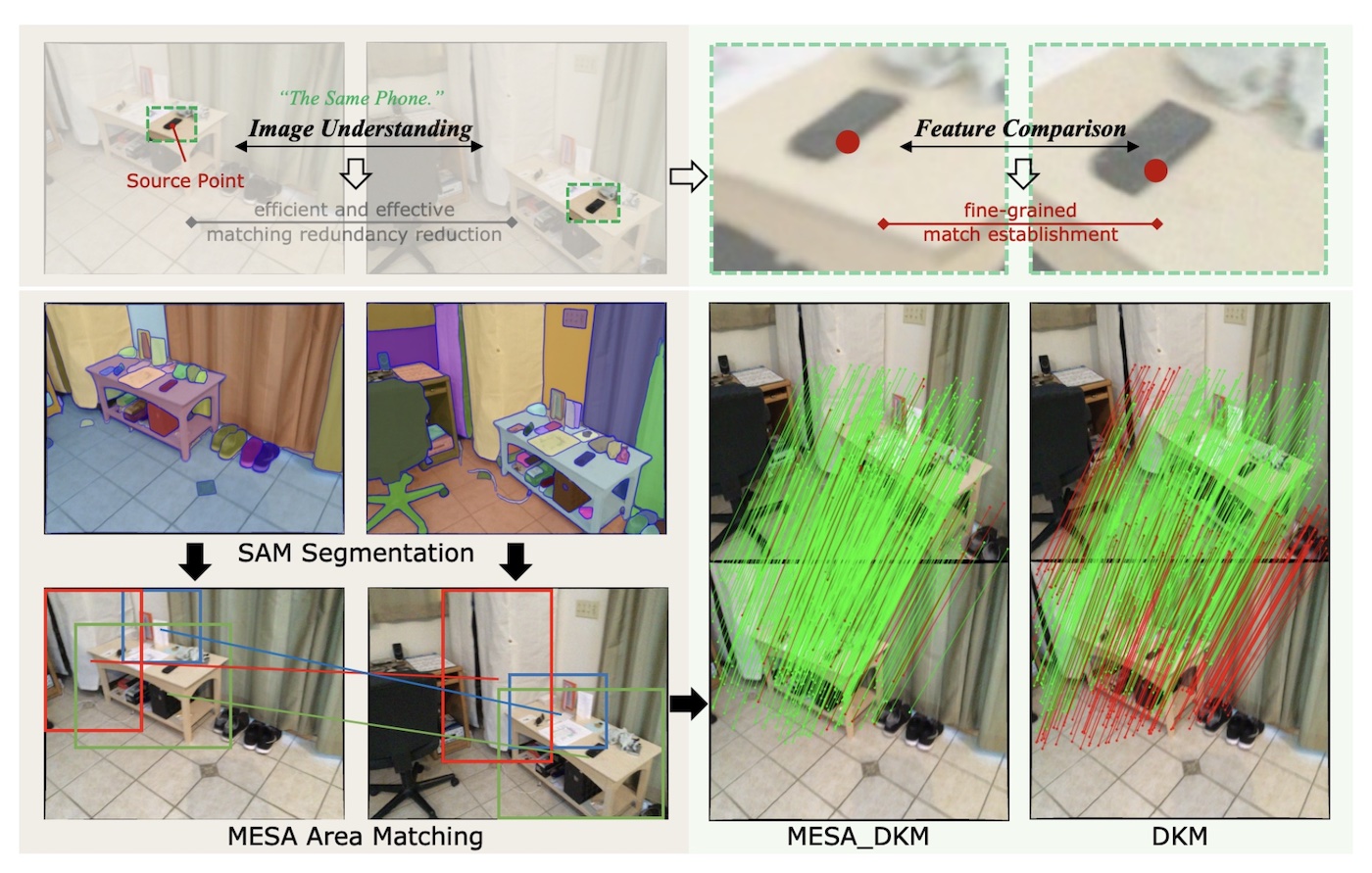
FEB 05, 2024
MESA and Co-Designing Model Architectures with Hardware
Short summaries of MESA and Co-Designing Model Architectures with Hardware, plus other highlights from the week.
JAN 31, 2024
Announcing Determined 0.27.1
We are excited to announce the 0.27.1 release of the Determined deep learning training platform!

JAN 31, 2024
Finetuning an LLM using HuggingFace + Determined
How to Finetune a TinyLlama-1.1B Model on Text-to-SQL
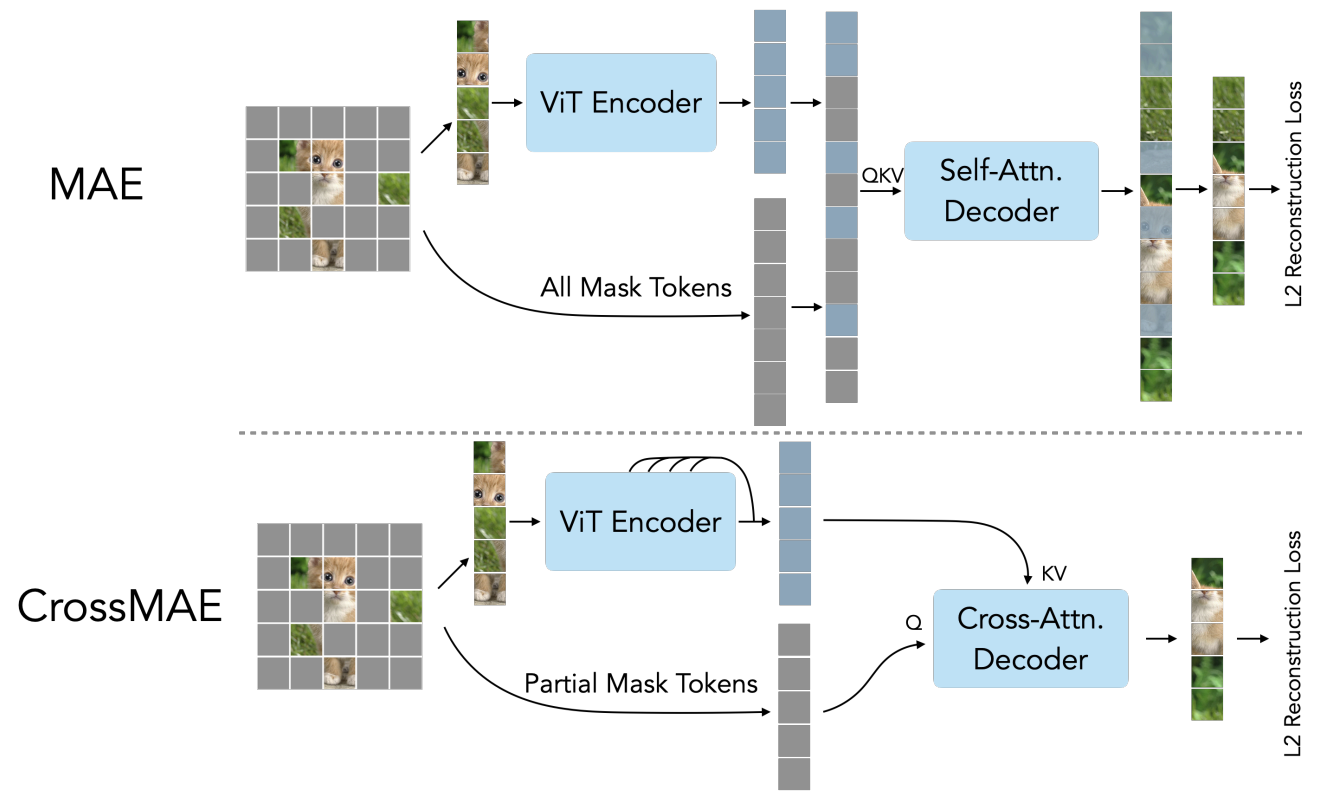
JAN 29, 2024
MambaByte, Multimodal Pathway, and CrossMAE
Short summaries of MambaByte, Multimodal Pathway, and CrossMAE, plus other highlights from the week.
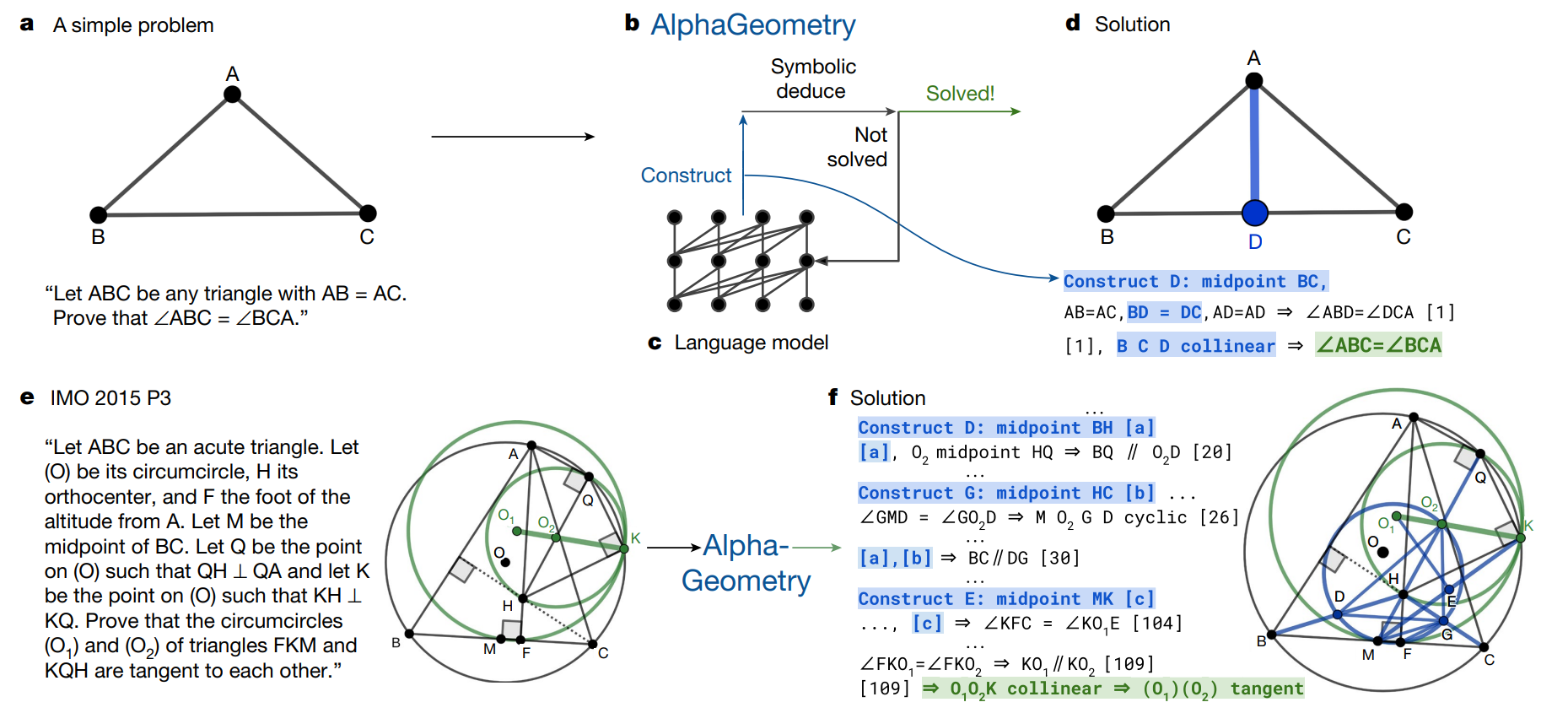
JAN 19, 2024
VMamba, Sleeper Agents, and AlphaGeometry
Visual Mamba for image processing, deceptive LLMs, and a geometry model from DeepMind caught our eye last week.

JAN 12, 2024
Unsloth, V-star, and TOFU
A new open source library for faster LLM finetuning, a multimodal guided visual search algorithm, and a new unlearning task for LLMs caught our eye last week.

JAN 08, 2024
Mobile ALOHA, AppAgent, Virtual Token Counter, and Time Vectors
Here’s what happened in AI the past few weeks.

DEC 19, 2023
NeurIPS 2023 - What's the buzz?
What we took away from attending NeurIPS ‘23 last week.